Database normalization is a process used to organize a database into tables and columns. There are three main forms: first normal form , second normal form, and third normal form. The main idea is each table should be about a specific topic and only supporting topics included. Take a spreadsheet containing the information as an example, where the data contains salespeople and customers serving several purposes:
- Identify salespeople in your organization
- List all customers your company calls upon to sell a product
- Identify which salespeople call on specific customers.
By limiting a table to one purpose you reduce the number of duplicate data contained within your database. This eliminates some issues stemming from database modifications.
To achieve these objectives, we’ll use some established rules. This is called database normalization. As you apply these rules, new tables are formed. The progression from unruly to optimized passes through several normal forms: first, second, and third normal form.
As tables satisfy each successive database normalization form, they become less prone to database modification anomalies and more focused toward a sole purpose or topic. Before we move on be sure you understand the definition of a database table.
Reasons for Database Normalization
There are three main reasons to normalize a database. The first is to minimize duplicate data, the second is to minimize or avoid data modification issues, and the third is to simplify queries.
As we go through the various states of normalization we’ll discuss how each form addresses these issues, but to start, let’s look at some data which hasn’t been normalized and discuss some potential pitfalls.
I think once you understand the issues, you better appreciate normalization. Consider the following table:
The first thing to notice is this table serves many purposes including:
- Identifying the organization’s salespeople
- Listing the sales offices and phone numbers
- Associating a salesperson with an sales office
- Showing each salesperson’s customers
As a DBA this raises a red flag. In general I like to see tables that have one purpose. Having the table serve many purposes introduces many of the challenges; namely, data duplication, data update issues, and increased effort to query data.
Data Duplication and Modification Anomalies
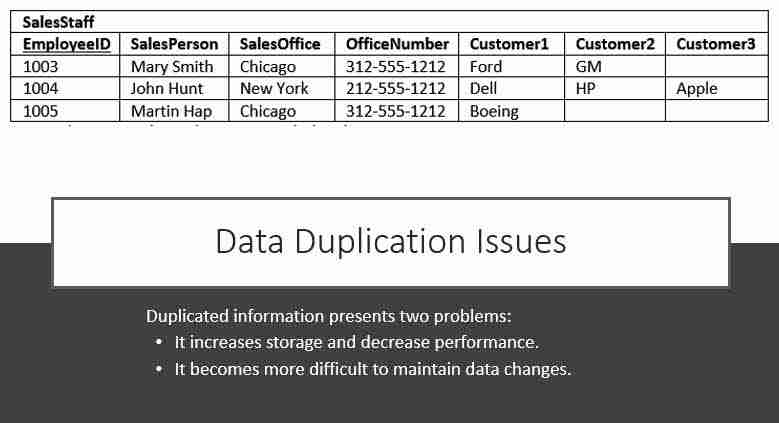
Notice that for each SalesPerson we have listed both the SalesOffice and OfficeNumber. There are duplicate salesperson data. Duplicated information presents two problems:
- It increases storage and decrease performance.
- It becomes more difficult to maintain data changes.
For example:
Consider if we move the Chicago office to Evanston, IL. To properly reflect this in our table, we need to update the entries for all the SalesPersons currently in Chicago. Our table is a small example, but you can see if it were larger, that potentially this could involve hundreds of updates.
These situations are modification anomalies. Database normalization fixes them. There are three modification anomalies that can occur:
Insert Anomaly

There are facts we cannot record until we know information for the entire row. In our example we cannot record a new sales office until we also know the sales person.
Why? Because in order to create the record, we need provide a primary key. In our case this is the EmployeeID.
Update Anomaly

In this case we have the same information in several rows.
For instance if the office number changes, then there are multiple updates that need to be made. If we don’t update all rows, then inconsistencies appear.
Deletion Anomaly

Removal of a row causes removal of more than one set of facts. For instance, if John Hunt retires, then deleting that row cause us to lose information about the New York office.
Database Normalization Helps with Search and Sort Issues
The last reason we’ll consider is making it easier to search and sort your data. In the SalesStaff table if you want to search for a specific customer such as Ford, you would have to write a query like
SELECT SalesOffice
FROM SalesStaff
WHERE Customer1 = ‘Ford’ OR
Customer2 = ‘Ford’ OR
Customer3 = ‘Ford’Clearly if the customer were somehow in one column our query would be simpler. Also, consider if you want to run a query and sort by customer. 
Our current table makes this tough. You would have to use three separate UNION queries! You can eliminate or reduce these anomalies by separating the data into different tables. This puts the data into tables serving a single purpose.
The process to redesign the table is database normalization.
Database Normalization Definition
There are three common forms of database normalization: 1st, 2nd, and 3rd normal form. They are also abbreviated as 1NF, 2NF, and 3NF respectively.
There are several additional forms, such as BCNF, but I consider those advanced, and not too necessary to learn in the beginning.
The forms are progressive, meaning that to qualify for 3rd normal form a table must first satisfy the rules for 2nd normal form, and 2nd normal form must adhere to those for 1st normal form. Before we discuss the various forms and rules in detail, let’s summarize the various forms:
- First Normal Form – The information is stored in a relational table with each column containing atomic values. There are no repeating groups of columns.
- Second Normal Form – The table is in first normal form and all the columns depend on the table’s primary key.
- Third Normal Form – the table is in second normal form and all of its columns are not transitively dependent on the primary key
If the rules don’t make too much sense, don’t worry. we take a deep dive into them here!
Our Sample Data for Normalization
Before we go too much further let’s look at the sample table we’ll use to demonstrate database normalization.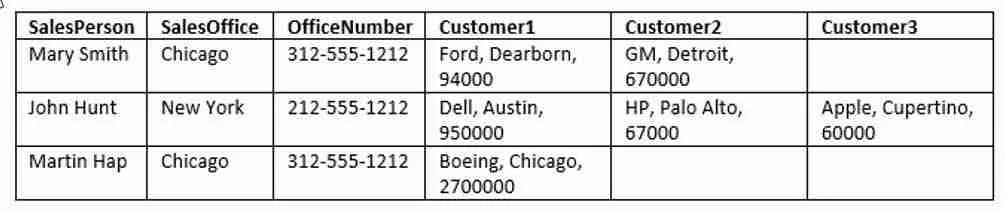
Before we get into the definition see if you can find some potential problems with this table’s setup. At a glance, here is what worries me:
- There are several “topics” covered in one table: salespeople, offices, and customers.
- The Customers are repeated as columns.
- The customer addresses are within on text field.
Let’s learn more about the first normal form of database normalization to see what we can do to make our table better.
First Normal Form (1NF) Database Normalization
The first step to constructing the right SQL table is to ensure that the information is in its first normal form. When a table is in its first normal form, searching, filtering, and sorting information is easier.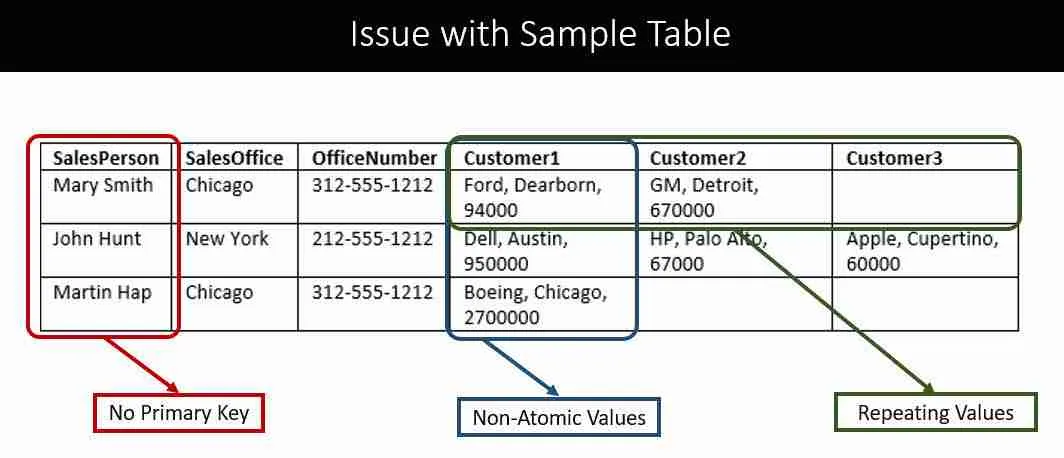
The rules to satisfy the 1st normal form are:
- When the data is in a database table. The table stores information in rows and columns where one or more columns, called the primary key, uniquely identify each row.
- Each column has atomic values and should be not repeating groups of columns.
Tables cannot have sub-columns in the first normal form. That is, you cannot list multiple cities in one column and separate them with a semi-colon.
Atomic Values
When a value is atomic, we don’t further subdivide the value. For example, the value “Chicago” is atomic; whereas “Chicago; Los Angeles; New York” is not.
Related to this requirement is the concept that a table should not have repeating groups of columns such as Customer1Name, Customer2Name, and Customer3Name.
Read More: Primary Key vs Foreign Key – Data Modeling Tips >>
First Normal Form Case Study
Let’s take a look at our sample data. Notice there are two “topics” covered within the table: sales staff and related information, and customer.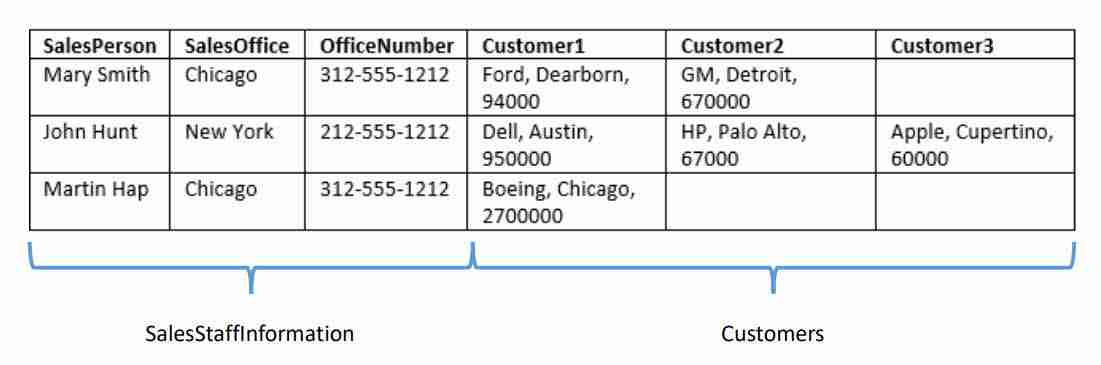
Let’s use those two topics as our basis to design our initial tables. If left as-is, and we don’t appply database normalization rules we end up with these issue: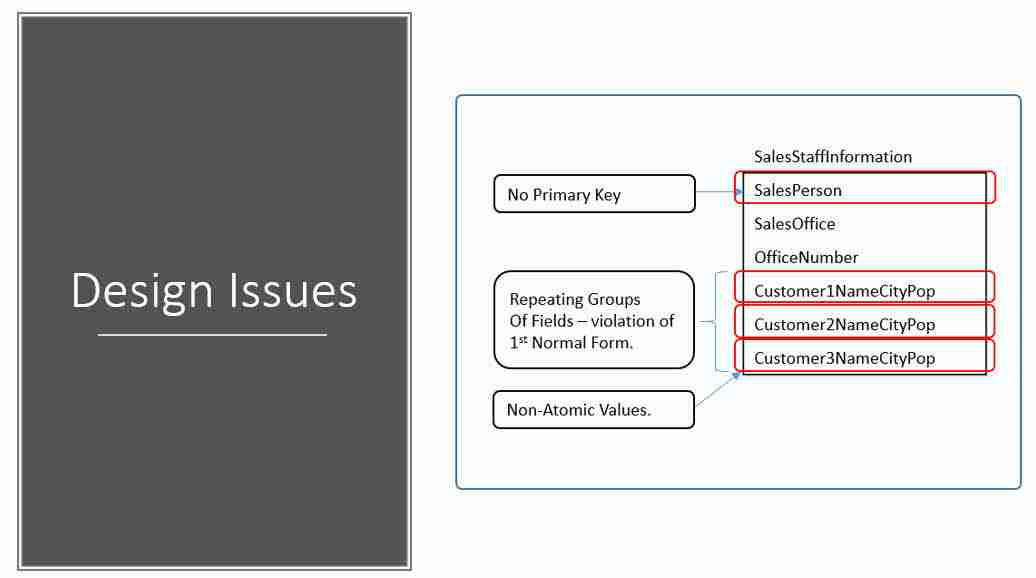
Check out the example below. Here you see we removed the offending repeating column name groups. We replaced them with a new table to house the one or more customers.
The repeated column groups in the Customer Table are now linked to the EmployeeID Foreign Key. As described in the Data Modeling lesson, a foreign key is a value that matches the primary key of another table.
In this case, the customer table holds the corresponding EmployeeID for the SalesStaffInformation row. Here is our data in the first normal form.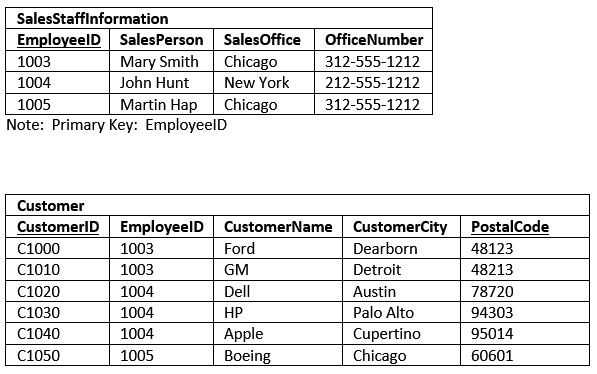
First Normal Form (1NF) Improvements
This design is superior to our original table in several ways:
- The original design limited each SalesStaffInformation entry to three customers. In the new design, the number of customers associated to each design is practically unlimited.
- The Customer, which is our original data, is nearly impossible to sort. You could, if you used the UNION statement, but it would be cumbersome. Now, it is simple to sort customers.
- The same holds true for filtering on the customer table. It is much easier to filter on one customer name related column than three.
- The design eliminates the insert and deletion anomalies for Customer. You can remove all the customers for a SalesPerson without having to remove the entire SalesStaffInformation row.
Modification anomalies are still in both tables, but these are fixed once we reorganize them as 2nd normal form.
Second Normal Form (2NF) Database Normalization
Now it is time to look at the second normal form. I like to think the reason we place tables in 2nd normal form is to narrow them to a single purpose. Doing so brings clarity to the database design, makes it easier for us to describe and use a table, and tends to remove modification anomalies.
This stems from the primary key identifying the main topic at hand, such as identifying buildings, employees, or classes, and the columns, serving to add meaning through descriptive attributes.
An EmployeeID isn’t much on its own, but add a name, height, hair color and age, and now you’re starting to describe a real person.
So what is the definition of 2nd normal form?
Second Normal Form (2NF) Definition
A table is in 2nd Normal Form if:
- The table is in 1st normal form, and
- All the non-key columns are dependent on the table’s primary key.
We already know about the 1st normal form, but what about the second requirement? Let me try to explain.
The primary key provides a means to uniquely identify each row in a table. When we talk about columns depending on the primary key, we mean, that to find a particular value, such as what color is Kris’ hair, you would first have to know the primary key, such as an EmployeeID, to look up the answer.
Key Question to Ask Yourself
Once you identify a table’s purpose, then look at each of the table’s columns and ask yourself, “Does this column serve to describe what the primary key identifies?”
- If you answer “yes,” then the column is dependent on the primary key and belongs in the table.
- If you answer “no,” then you should move the column to a different table.
When all the columns relate to the primary key, they naturally share a common purpose, such as describing an employee. That is why I say that when a table is in second normal form, it has a single purpose, such as storing employee information.
Issues with our Example Data Model
So far, we have taken our example to the first normal form, and it has several issues.
The first issue is that there are several attributes which don’t completely rely on the entire Customer table primary key.
For a given customer, it doesn’t make sense that you should have to know both the CustomerID and EmployeeID to find the customer.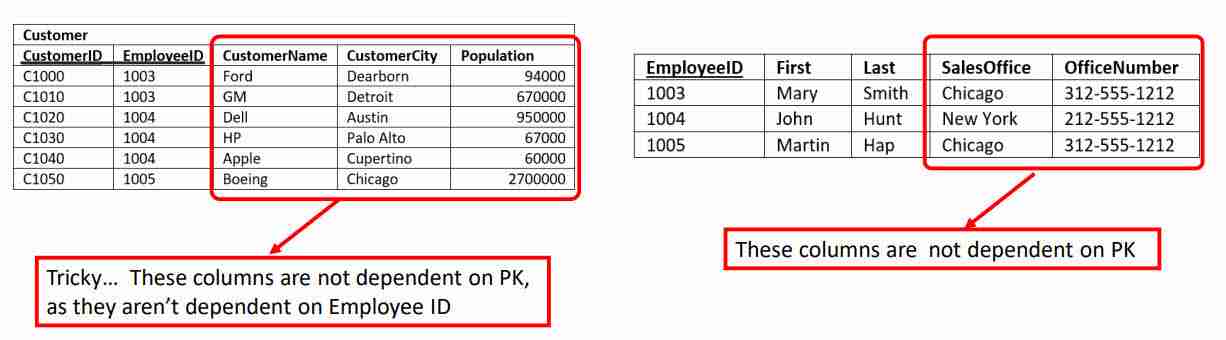
It stands to reason you should only need to know the CustomerID. Given this, the Customer table isn’t in 2nd normal form as there are columns that aren’t dependent on the full primary key. We should move them to another table.
The second issue is the SalesStaffInformation table has two columns which aren’t dependent on the EmployeeID. Though the SalesOffice and OfficeNumber columns describe which office the SalesPerson is based out of, they don’t serve to describe the employee.
You can see these issues outline in red below.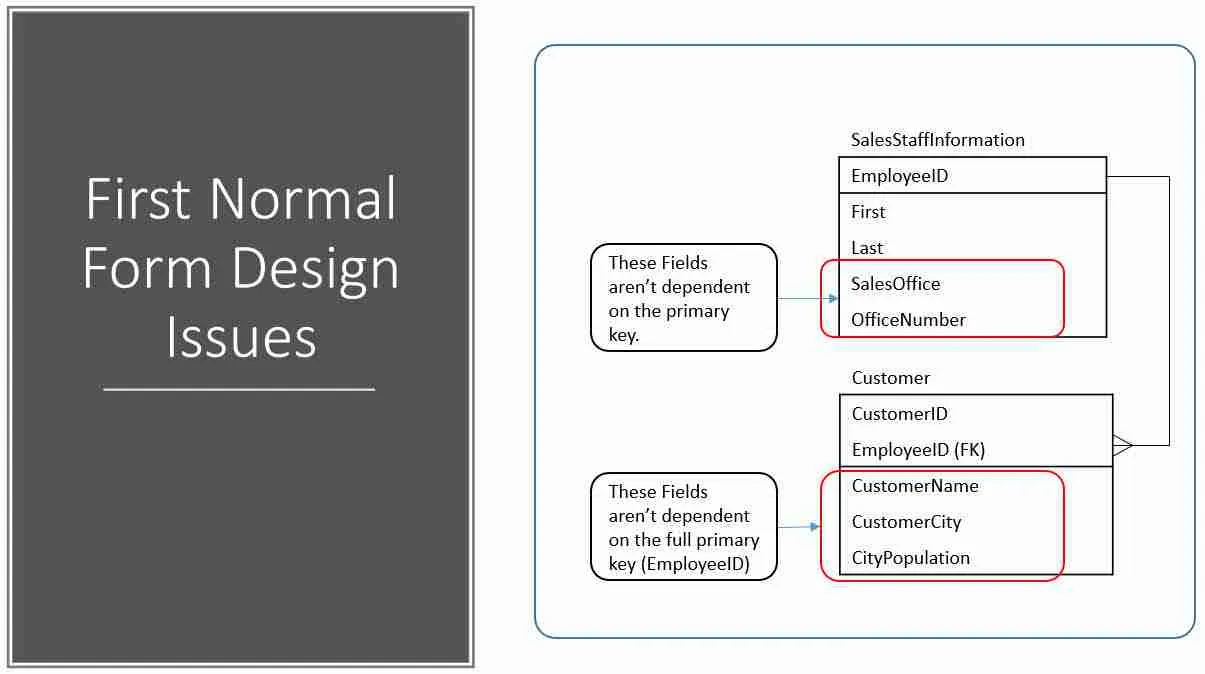
Fix the Model to Second Normal Form (2NF) Standards
Since the columns outlined in red aren’t completely dependent on the table’s primary key, it stands to reason they belong elsewhere. In both cases, move the columns to new tables.
In the case of SalesOffice and OfficeNumber, let’s create the SalesOffice table. I added a foreign key to SalesStaffInformaiton so we can still describe in which office a salesperson is based.
The changes to make Customer a second normal form table are a little trickier. Rather than move the offending columns CustomerName, CustomerCity, and CustomerPostalCode to new table, recognize that the issue is EmployeeID!
The three columns don’t depend on this part of the key. Really this table is trying to serve two purposes:
- To show which customers each employee calls to make sales.
- To find customers and their locations.
For the moment remove EmployeeID from the table. Now the table’s purpose is clear, it is to find and describe each customer.
Move Sample Data to Second Normal Form
Now let’s create a table named SalesStaffCustomer to describe which customers a salesperson calls upon. This table has two columns CustomerID and EmployeeID. Together, they form a primary key. Separately, they are foreign keys to the Customer and SalesStaffInformation tables, respectively.
The data model is show below in second normal form.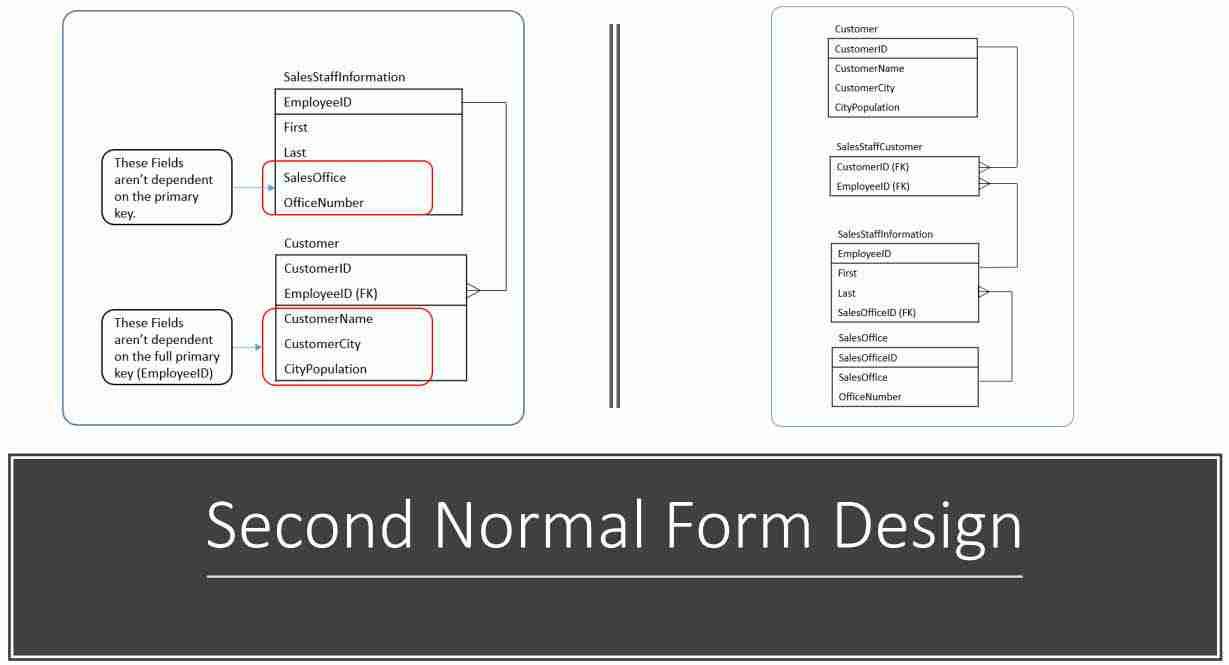
To better visualize this, here are the tables with data.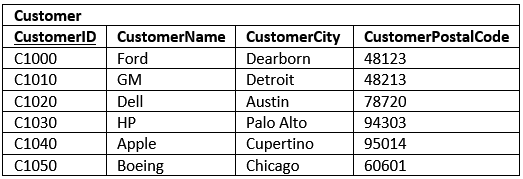
Second Normal Form Benefits
As you review the data in the tables notice moving the data to second normal form mostly removed the redundancy. Also, see if you can find any update, insert, or deletion anomalies. Those too are gone. You can now remove all the salespeople yet keep customer records. Also, if all the SalesOffices close, it doesn’t mean you have to delete the records containing salespeople.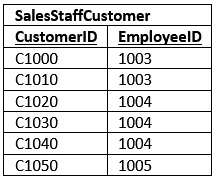
The SalesStaffCustomer table is a strange one. It’s just all keys! Database architects call this an intersection table. An intersection table is useful when you need to model a many-to-many relationship.
Each column is a foreign key. If you look at the data model, you’ll notice that there is a one-to-many relationship to this table from SalesStaffInformation and another from Customer. In effect the table allows you to bridge the two tables together.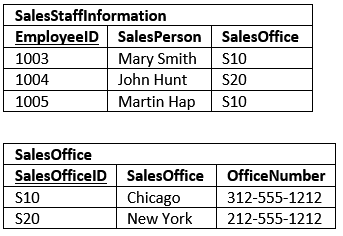
For all practical purposes this is a workable database. Three out of the four tables are even in third normal form, but there is one table which still has a minor issue, preventing it from being so.
Once a table is in second normal form, the design guarantees that every column is dependent on the primary key, or as I like to say, the table serves a single purpose. But what about relationships among the columns? Could there be dependencies between columns that could cause an inconsistency? A table having both columns for an employee’s age and birth date is spelling trouble, there lurks an opportunity for data inconsistency!
How are these addressed? By the third normal form.
Third Normal Form (3NF) Database Normalization
A table is in third normal form if:
- A table is in 2nd normal form.
- It contains only columns that are non-transitively dependent on the primary key
Wow! That’s a mouthful. What does non-transitively dependent mean? Let’s break it down.
Transitive
When something is transitive, then a meaning or relationship is the same in the middle as it is across the whole. If it helps think of the prefix trans as meaning “across.” When something is transitive, then if something applies from the beginning to the end, it also applies from the middle to the end.
Since ten is greater than five, and five is greater than three, you can infer that ten is greater than three.
In this case, the greater than comparison is transitive. In general, if A is greater than B, and B is greater than C, then it follows that A is greater than C.
If you’re having a hard time wrapping your head around “transitive” I think for our purpose it is safe to think “through” as we’ll be reviewing to see how one column in a table may be related to others, through a second column.
Dependence
An object has a dependence on another object when it relies upon it. In the case of databases, when we say that a column has a dependence on another column, we mean that the value can be derived from the other. For example, my age is dependent on my birthday. Dependence also plays an important role in the definition of the second normal form.
Transitive Dependence
Now let’s put the two words together to formulate a meaning for transitive dependence that we can understand and use for database columns.
I think it is simplest to think of transitive dependence to mean a column’s value relies upon another column through a second intermediate column.
Consider three columns: AuthorNationality, Author, and Book. Column values for AuthorNationality and Author rely on the Book; once the book is known, you can find out the Author or AuthorNationality. But also notice that the AuthorNationality relies upon Author. That is, once you know the Author, you can determine their nationality. In this sense then, the AuthorNationality relies upon Book, via Author. This is a transitive dependence.
This can be generalized as being three columns: A, B and PK. If the value of A relies on PK, and B relies on PK, and A also relies on B, then you can say that A relies on PK though B. That is A is transitively dependent on PK.
Transitive Dependence Examples
Let’s look at some examples to understand further.Key (PK) Column A Column B Transitive Dependence? PersonID FirstName LastName No, In Western cultures a person’s last name is based on their father’s LastName, whereas their FirstName is given to them. PersonID BodyMassIndex IsOverweight Yes, BMI over 25 is considered overweight.It wouldn’t make sense to have the value IsOverweight be true when the BodyMassIndex was < 25. PersonID Weight Sex No:There is no direct link between the weight of a person and their sex. VehicleID Model Manufacturer Yes:Manufacturers make specific models. For instance, Ford creates the Fiesta; whereas, Toyota manufacturers the Camry.
To be non-transitively dependent, then, means that all the columns are dependent on the primary key (a criteria for 2nd normal form) and no other columns in the table.
Issues with our Example Data Model
Let’s review what we have done so far with our database. You’ll see that I’ve found one transitive dependency:
CustomerCity relies on CustomerPostalCode which relies on CustomerID
Generally speaking a postal code applies to one city. Although all the columns are dependent on the primary key, CustomerID, there is an opportunity for an update anomaly as you could update the CustomerPostalCode without making a corresponding update to the CustomerCity.
We’ve identified this issue in red.
Fix the Model to Third Normal Form (3NF) Standards
In order for our model to be in third normal form, we need to remove the transitive dependencies. As we stated our dependency is:
CustomerCity relies on CustomerPostalCode which relies on CustomerID
It is OK that CustomerPostalCode relies on CustomerID; however, we break 3NF by including CustomerCity in the table. To fix this we’ll create a new table, PostalCode, which includes PostalCode as the primary key and City as its sole column.
The CustomerPostalCode remains in the customer table. The CustomerPostalCode can then be designated a foreign key. In this way, through the relation, the city and postal code is still known for each customer. In addition, we’ve eliminated the update anomaly.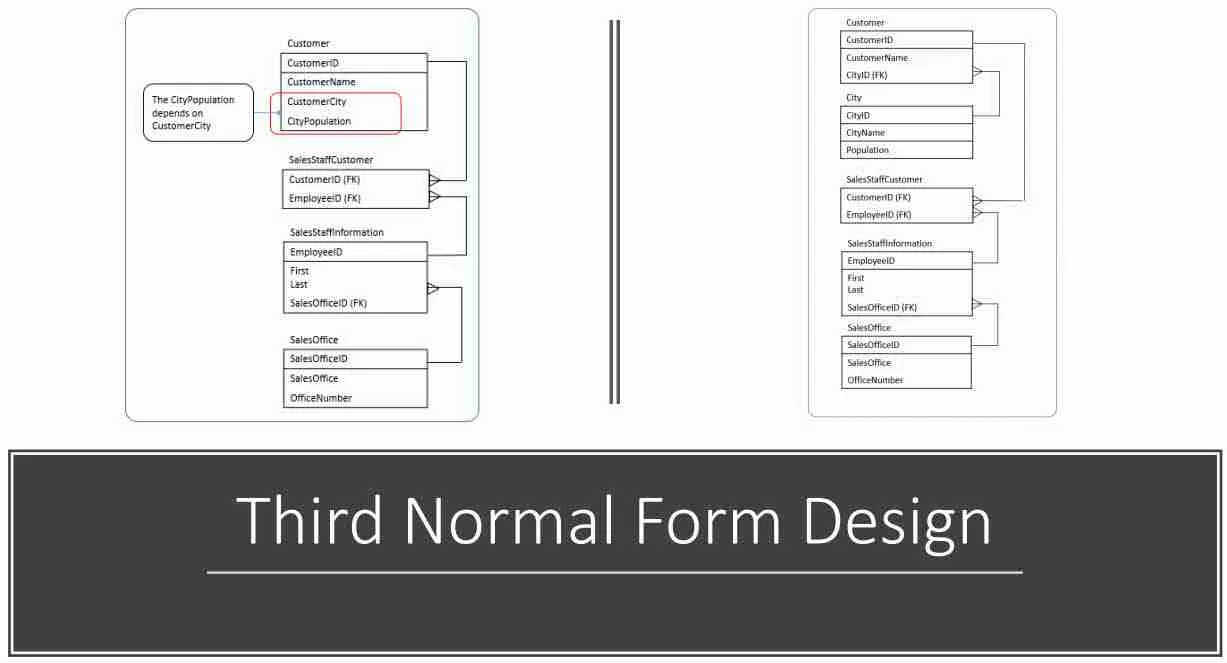
To better visualize this, here are the Customer and PostalCode tables with data.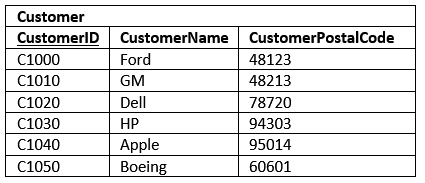
Now each column in the customer table is dependent on the primary key. Also, the columns don’t rely on one another for values. Their only dependency is on the primary key.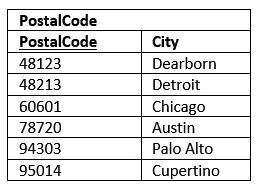
The same holds true for the PostalCode table.
At this point our data model fulfills the requirements for the third normal form. For most practical purposes this is usually sufficient; however, there are cases where even further data model refinements can take place. If you are curious to know about these advanced normalization forms, I would encourage you to read about BCNF (Boyce-Codd Normal Form) and more!
Conclusion – Can Database Normalization Get out of Hand?
Can database normalization be taken too far? You bet! There are times when it isn’t worth the time and effort to fully normalize a database. In our example you could argue to keep the database in second normal form, that the CustomerCity to CustomerPostalCode dependency isn’t a deal breaker.
I think you should normalize if you feel that introducing update or insert anomalies can severely impact the accuracy or performance of your database application. If not, then determine whether you can rely on the user to recognize and update the fields together.
There are times when you’ll intentionally denormalize data. If you need to present summarized or complied data to a user, and that data is very time consuming or resource intensive to create, it may make sense to maintain this data separately.
One of My Experiences with Database Normalization
Several years ago I developed a large engineering change control system which, on the home page, showed each engineer’s the parts, issues, and tasks requiring their attention. It was a database wide task list. The task list was rebuilt on-the-fly in real-time using views. Performance was fine for a couple of years, but as the user base grew, more and more DB resources were being spent to rebuild the list each time the user visited the home page.
I finally had to redesign the DB. I replaced the view with a separate table that was initially populated with the view data and then maintained with code to avoid anomalies. We needed to create complicated application code to ensure it was always up-to-date.
For the user experience it was worth it. We traded off complexity in dealing with update anomalies for improved user experience.
Next Steps.
If you’re looking to learn more about database design concepts. I would recommend the following articles:



Leave a Reply