Correlated subqueries are used to tie an inner query’s criteria to values within the outer query. They are powerful technique to avoid “hard coding” values. In this article look at a couple example and compare a correlated sub query to a join.
All the examples for this lesson are based on Microsoft SQL Server Management Studio and the AdventureWorks2012 database. Get started using these free tools with my Guide Getting Started Using SQL Server.
Correlated Queries
There are ways to incorporate the outer query’s values into the subquery’s clauses. These types of queries are called correlated subqueries, since the results from the subquery are connected, in some form, to values in the outer query. They are sometimes called synchronized queries.
If you’re having trouble knowing what correlate means, check out this definition from Google:
Correlate: “have a mutual relationship or connection, in which one thing affects or depends on another.”
Google
A typical use for a correlated subquery is used one of the outer query’s columns in the inner query’s WHERE clause. This is common sense in many cases you want to restrict the inner query to a subset of data.
Read More: SQL Subqueries – The Ultimate Guide >>
Example
We’ll provide a correlated subquery example by reporting back each SalesOrderDetail LineTotal, and the Average LineTotal’s for the overall Sales Order.
This request differs significantly from our earlier examples since the average we’re calculating varies for each sales order.
This is where correlated subqueries come into play. We can use a value from the outer query and incorporate it into the filter criteria of the subquery.
Let’s take a look at how we calculate the average line total. To do this this I’ve put together an illustration that shows the SELECT statement with subquery.
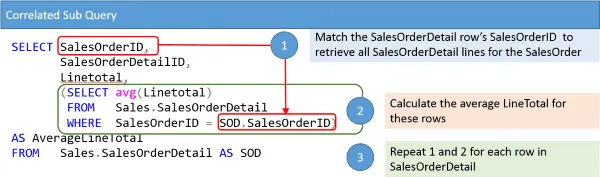
To further elaborate on the diagram. The SELECT statement consists of two portions, the outer query, and the subquery. The outer query is used to retrieve all SalesOrderDetail lines. The subquery is used to find and summarize sales order details lines for a specific SalesOrderID.
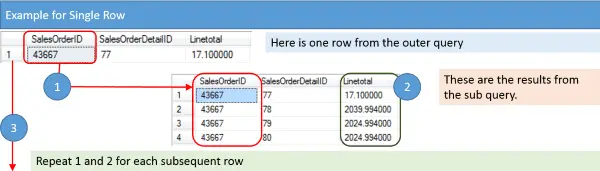
If I was to verbalize the steps we are going to take, I would summarize them as:
- Get the SalesOrderID.
- Return the Average LineTotal from All SalesOrderDetail items where the SalesOrderID matches.
- Continue on to the next SalesOrderID in the outer query and repeat steps 1 and 2.
The query you can run in the AdventureWork2012 database is:
SELECT SalesOrderID,
SalesOrderDetailID,
LineTotal,
(SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = SOD.SalesOrderID)
AS AverageLineTotal
FROM Sales.SalesOrderDetail SOD
Here are the results of the query:
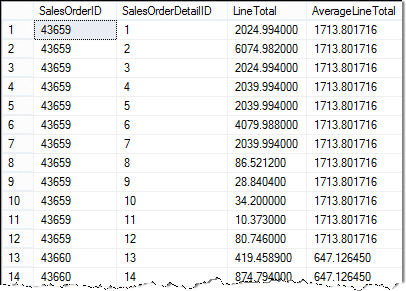
There are a couple of items to point out.
- You can see I used column aliases to help make the query results easier to read.
- I also used a table alias, SOD, for the outer query. This makes it possible to use the outer query’s values in the subquery. Otherwise, the query isn’t correlated!
- Using the table aliases make it unambiguous which columns are from each table.
Breaking down Correlated Nested Queries
Let’s now try to break this down using SQL.
To start let’s assume we’re going to just get our example for SalesOrderDetailID 20. The corresponding SalesOrderID is 43661.
To get the average LineTotal for this item is easy
SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43661
This returns the value 2181.765240.
Now that we have the average we can plug it into our query
SELECT SalesOrderID,
SalesOrderDetailID,
LineTotal,
2181.765240 AS AverageLineTotal
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID = 20
Using subqueries this becomes
SELECT SalesOrderID,
SalesOrderDetailID,
LineTotal,
(SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = 43661) AS AverageLineTotal
FROM Sales.SalesOrderDetail
WHERE SalesOrderDetailID = 20
Final query is:
SELECT SalesOrderID,
SalesOrderDetailID,
LineTotal,
(SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = SOD.SalesOrderID) AS AverageLineTotal
FROM Sales.SalesOrderDetail AS SOD
Using with a Different Table
A Correlated subquery, or for that matter any subquery, can use a different table than the outer query. This can come in handy when you’re working with a “parent” table, such as SalesOrderHeader, and you want to include in result a summary of child rows, such as those from SalesOrderDetail.
Let’s return the OrderDate, TotalDue, and number of sales order detail lines. To do this we can use the following diagram to gain our bearings:
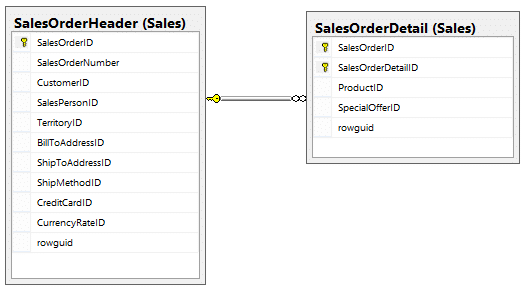
To do this we’ll include a correlated subquery in our SELECT statement to return the COUNT of SalesOrderDetail lines. We’ll ensure we are counting the correct SalesOrderDetail item by filtering on the outer query’s SalesOrderID.
Here is the final SELECT statement:
SELECT SalesOrderID,
OrderDate,
TotalDue,
(SELECT COUNT(SalesOrderDetailID)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = SO.SalesOrderID) as LineCount
FROM Sales.SalesOrderHeader SO
The results are:
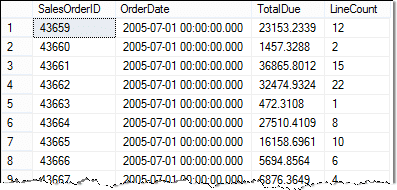
Some things to notice with this example are:
- The subquery is selecting data from a different table than the outer query.
- I used table and column aliases to make it easier to read the SQL and results.
- Be sure to double-check your where clause! If you forget to include the table name or aliases in the subquery WHERE clause, the query won’t be correlated.
Correlated Subqueries versus Inner Joins
It is important to understand that you can get that same results using either a subquery or join. Though both return the same results, there are advantages and disadvantages to each method!
Consider the last example where we count line items for SalesHeader items.
SELECT SalesOrderID,
OrderDate,
TotalDue,
(SELECT COUNT(SalesOrderDetailID)
FROM Sales.SalesOrderDetail
WHERE SalesOrderID = SO.SalesOrderID) as LineCount
FROM Sales.SalesOrderHeader SO
This same query can be done using an INNER JOIN along with GROUP BY as
SELECT SO.SalesOrderID,
OrderDate,
TotalDue,
COUNT(SOD.SalesOrderDetailID) as LineCount
FROM Sales.SalesOrderHeader SO
INNER JOIN Sales.SalesOrderDetail SOD
ON SOD.SalesOrderID = SO.SalesOrderID
GROUP BY SO.SalesOrderID, OrderDate, TotalDue
Which one is faster?
You’ll find that many folks will say to avoid subqueries as they are slower. They’ll argue that the correlated subquery has to “execute” once for each row returned in the outer query, whereas the INNER JOIN only has to make one pass through the data.
Myself? I say check out the query plan. I followed my own advice for both of the examples above and found the plans to be the same!
That isn’t to say the plans would change if there was more data, but my point is that you shouldn’t just make assumptions. Most SQL DBMS optimizers are really good at figuring out the best way to execute your query. They’ll take your syntaxes, such as a subquery, or INNER JOIN, and use them to create an actual execution plan.
Which one is Easier to Read?
Depending upon what you’re comfortable with you may find the INNER JOIN example easier to read than the correlated query. Personally, in this example, I like the correlated subquery as it seems more direct. It is easier for me to see what is being counted.
In my mind, the INNER JOIN is less direct. First you have to see that all the sales details rows are being returned hand then summarized. You don’t really get this until you read the entire statement.
Which one is Better?
Let me know what you think. I would like to hear whether you would prefer to use the correlated subquery or INNER JOIN example.
Correlated Subqueries in HAVING Clause
As with any other subquery, subqueries in the HAVING clause can be correlated with fields from the outer query.
Suppose we further group the job titles by marital status and only want to keep those combinations of job titles and martial statuses whose vacation hours are greater than those for their corresponding overall marital status?
In other words, we want to answer a question similar to “do married accountants have, on average, more remaining vacation, than married employees in general?”
One way to find out is to us the following query:
SELECT JobTitle,
MaritalStatus,
AVG(VacationHours)
FROM HumanResources.Employee AS E
GROUP BY JobTitle, MaritalStatus
HAVING AVG(VacationHours) >
(SELECT AVG(VacationHours)
FROM HumanResources.Employee
WHERE HumanResources.Employee. MaritalStatus =
E.MaritalStatus)
There are a couple of things to point out. First, notice that I aliased the Employee as “E” in the outer query. This allows me to reference the outer table within the inner query.
Also, with the correlated query, only fields used in the GROUP BY can be used in the inner query. For instance, for kicks and grins, I tried replacing MaritalStatus with Gender and got an error.
SELECT JobTitle,
MaritalStatus,
AVG(VacationHours)
FROM HumanResources.Employee AS E
GROUP BY JobTitle, MaritalStatus
HAVING AVG(VacationHours) >
(SELECT AVG(VacationHours)
FROM HumanResources.Employee
WHERE HumanResources.Employee. Gender =
E. Gender)
Is a broken query. If you try to run it you’ll get the following error:
Column ‘HumanResources.Employee.Gender’ is invalid in the HAVING clause because it is not contained in either an aggregate function or the GROUP BY clause.



Leave a Reply