So what happens when you create a view, and then later someone else changes the underlying tables? In this article let’s explore a simple scenario, check out how the SQL view handles the change, and what we can learn from viewing the data dictionary.
Create View Scenario
Imagine we are accepting data from a table that is the same in three separate systems. We do some cleanup activities on the data, saved the cleaned up version, and finally to help out the user, create a view to pull it all together.
It’s a simple process which I diagramed for you below:
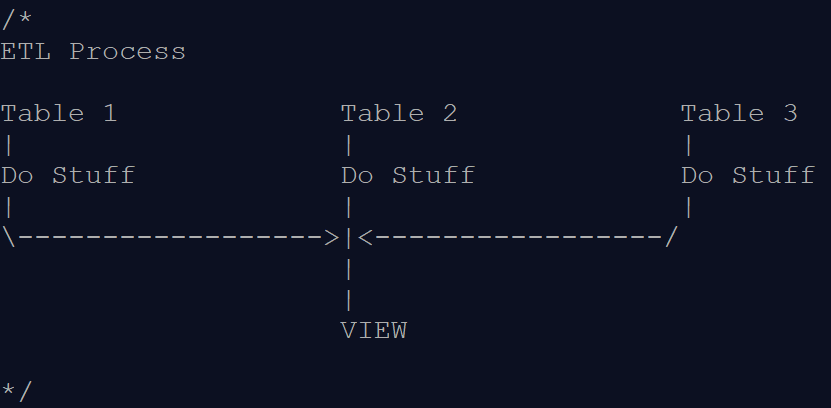
The general idea is that we create three tables and offer it up as a view.
I created the scenario using the following SQL:
-- setup scenario
create table T1 (ID int, City varchar(20));
insert into T1 (ID, City) values (1, 'Atlanta'), (2, 'Chicago'), (3, 'New York')
create table T2 (ID int, City varchar(20));
insert into T2 (ID, City) values (11, 'London'), (12, 'Frankfurt'), (13, 'Rome')
create table T3 (ID int, City varchar(20));
insert into T3 (ID, City) values (21, 'Tokyo'), (22, 'Sydney'), (23, 'Seoul')
-- make it easier on users, create a view!
create view TV
as
select * from T1 union
select * from T2 union
select * from T3This works perfectly and it is easy to get the data. Just select from the view to see the results:
select *
from TV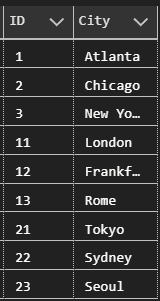
But when the source tables are changed by the developers, and we’re processing and cleaning data, but not explicitly using every view, we can get into a situation where some field changes go unnoticed and our CREATE VIEW definition is out of date.
CREATE VIEW issues due to Underlying Tables Modifications
To simulate a possible change, let’s drop the three tables, change some columns, and try the view:
drop table T1
create table T1 (ID int, Stat int, CityName varchar(20));
insert into T1 (ID, Stat, CityName) values (1, 0, 'Atlanta'), (2, 0, 'Chicago'), (3, 0, 'New York')
drop table T2
create table T2 (ID int, Stat int, CityName varchar(20));
insert into T2 (ID, Stat, CityName) values (11, 0, 'London'), (12, 0, 'Frankfurt'), (13, 0, 'Rome')
drop table T3
create table T3 (ID int, City varchar(20));
insert into T3 (ID, City) values (21, 'Tokyo'), (22, 'Sydney'), (23, 'Seoul')with the tables changed, what do you think will happen when we try to run our view?
What result will you expect to see from
select * from TVSurprisingly, it won’t throw an error. In fact, it is a bad situation. The query runs, but returns incorrect data!
Here are the results:
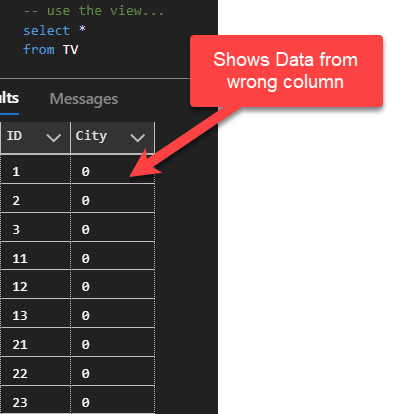
So what happened? Why are we seeing incorrect results?
Why CREATE VIEW is Causing Issues
In order to find an explanation, let’s go look at the VIEW’s SQL stored as the definition within the data dictionary.
We can lookup the columns used to create the view
select v.name, m.definition, c.*
from sys.views v
inner join sys.sql_modules m on v.object_id = m.object_id
inner join sys.columns c on v.object_id = c.object_id
where v.name = 'TV'This query uses three tables to pull together SQL Server’s perspective. I’m using sys.views to get the view, sys.sql_modules to get the text used in the CREATE VIEW command, and finally sys.columns to see what columns are defined in the view.
There are a couple in interesting items to note:
- The view definition remain in the form “select * from T1…”
- The columns we see in sys.columns are from the original table definition.
So what is going on?
Clearly the whenever we execute the command
select * from TVit isn’t looking at the view definition SQL and re-running that query. If the database did that, then select * would work fine.
Rather, the database is looking up the column definitions and incorporating those into the view. I’ll need to dig deeper to find the exact sql it is running, but from the information I have here, you can see view is ordinal based. It is based on the order of the two columns from sys.columns.
By looking at the final result, we can see the the query optimizer uses this out-of-date information to build the query.
Conclusion
In summary, it is best practice to not use “select *,” however, when you start working with data warehouses you quickly find that using full columns lists is a maintenance nightmare. You may find yourself using select * to cut down on coding. If you decide to go this route, be aware that any view you create using the select * method may become out of data as schemas in your source systems drift.



Leave a Reply