SQL subqueries make it possible for you to write queries that are more dynamic, and data driven. Think of them as query within another query.
In this article I’ll introduce you to subqueries and some of their high-level concepts. I will show you how to write a SQL subquery as part of the SELECT statement. Subqueries return two types of results: either a single value called a scalar value, or a table value, which is akin to a query result.
As you work through the examples, keep in mind they’re based Microsoft SQL Server Management Studio and the AdventureWorks2012 database. Get started using these free tools with my Guide Getting Started Using SQL Server.
Subqueries in SQL
Subqueries provide a powerful means to combine data from two tables into a single result. You can also call these nested queries. As the name implies, subqueries contain one or more queries, one inside the other.
Subqueries are very versatile and that can make them somewhat hard to understand. For most cases use them anywhere you can use an expression or table specification.
For example, you can use subqueries in the SELECT, FROM, WHERE, or HAVING clauses. A subquery may return either a single value or multiple rows.
A single value is also known as a scalar value.
Subquery Overview
Subqueries make it possible for you to write queries that are more dynamic and data driven. For instance using a subquery you can return all products whose ListPrice is greater than the average ListPrice for all products.
You can do this by having it first calculate the average price and then use this to compare against each product’s price.
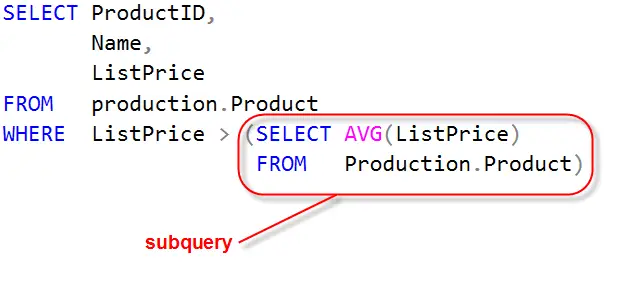
First Walk Through
Let’s break down this query so you can see how it works.
Step 1: First let’s run the subquery:
SELECT AVG(ListPrice) FROM Production.Product
It returns 438.6662 as the average ListPrice
Step 2: Find products greater than the average price by plugging in the average ListPrice value into our query’s comparison
SELECT ProductID,
Name,
ListPrice
FROM production.Product
WHERE ListPrice > 438.6662
Huge Benefit of SQL Subqueries
As you can see, by using the subquery we combined the two steps together. The subquery eliminated the need for us to find the average ListPrice and then plug it into our query.
This is huge! It means our query automatically adjusts itself to changing data and new averages.
Hopefully you’re seeing a glimpse into how subqueries can make your statements more flexible. In this case, by using a subquery we don’t need to know the value for the average list price.
We let the subquery do the work for us! The subquery calcuates the average value on-the-fly; there is no need for us to “update” the average value within the query.
Second Walkthrough
Being able to dynamically create the criterion for a query is very handy. Here we use a subquery to list all customers whose territories have sales below $5,000,000.
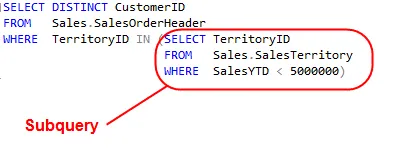
We build the list “live” with the IN operator, this avoid us from having to hard code the values.
It may help to see how to execute this query step by step:
Step 1: Run the subquery to get the list of territories that had year to date sales less than 5,000,000:
SELECT TerritoryID FROM Sales.SalesTerritory WHERE SalesYTD < 5000000
This returns 2,3,5,7,8 as a list of values.
Step 2: Now that we have a list of values we can plug them into the IN operator:
SELECT DISTINCT CustomerID
FROM Sales.SalesOrderHeader
WHERE TerritoryID IN (2,3,5,7,8)
Again, we could have just broken this down into multiple steps, but the disadvantage in doing so is we would have to constantly update the list of territories.
Now that you’ve see how we use a sub query in the SQL statement let’s take a look at using them in the WHERE clause.
Subqueries in the SELECT Clause
Queries used within a column list must return a single value. In this case, you can think of the subquery as a single value expression. The result returned is no different than the expression “2 + 2.” Of course, subqueries can return text as well, but you get the point!
The main SQL statement is called the outer query; it calls the subquery. Enclose subqueries in parenthesis, its required, but also makes them easier to spot.
Be careful when using subqueries. They can be fun to use, but as you add more to your query they can start to slow down your query.
Simple Subquery to Calculate Average
Let’s start out with a simple query to show SalesOrderDetail and compare that to the overall average SalesOrderDetail LineTotal. The SELECT statement we’ll use is:
SELECT SalesOrderID, LineTotal, (SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail) AS AverageLineTotal FROM Sales.SalesOrderDetail;
This query returns results as:
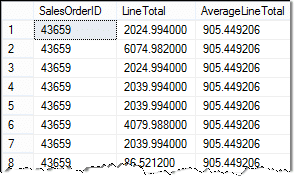
The average line total is calculated using the subquery shown in red.
SELECT AVG(LineTotal) FROM Sales.SalesOrderDetail
This result is then plugged back into the column list, and the query continues.
Observations
There are several things I want to point out:
- SQL requires that subqueries are enclosed in parenthesis.
- Subqueries using in a SELECT can only return one value. This should make sense, simply selecting a column returns one value for a row, and we need to follow the same pattern.
- In general, the subquery is run only once for the entire query, and its result reused. This is because the query result does not vary for each row returned.
- It is important to use aliases for the column names to improve readability.
Simple Subquery in Expression
A subquery’s result can be used in other expressions. Building on the previous example let’s use the subquery to determine how much our LineTotal varies from the average.
The variance is simply the LineTotal minus the Average Line total. In the following subquery, I’ve colored it blue. Here is the formula for the variance:
LineTotal - (SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail)
The SELECT statement enclosed in the parenthesis is the subquery. Like the earlier example, this query will run once, return a numeric value, which is then subtracted from each LineTotal value.
Here is the query in final form:
SELECT SalesOrderID,
LineTotal,
(SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail) AS AverageLineTotal,
LineTotal - (SELECT AVG(LineTotal)
FROM Sales.SalesOrderDetail) AS Variance
FROM Sales.SalesOrderDetail
Here is the result:
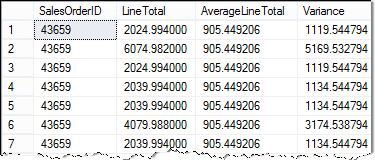
When working with subqueries in select statements I usually build and test the subquery SQL first. Do this to troubleshoot the pieces before you assemble your complex query! It is best to build them up little by little. By building and testing the various pieces separately, it really helps with debugging.
Subqueries in the WHERE clause
Let’s see how to write a subquery in the where clause. To do this we will use IN operator to test whether a value is part of the result the subquery returns.
Here is the general format:
SELECT column1, column2,..
FROM table1
WHERE column2 IN (subquery1)
An example makes this clearer. Suppose we want to find all sales orders made by a salesperson having a bonus greater than 5000 dollars.
To do this we’ll write two queries. The outer to find the sales orders, and an inner (the SQL subquery) to return SalePersonID for $5000 and above bonus earners.
I color coded the subquery so you can easily see it:
SELECT SalesOrderID
,OrderDate
,AccountNumber
,CustomerID
,SalesPersonID
,TotalDue
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IN (SELECT BusinessEntityID
FROM Sales.SalesPerson
WHERE Bonus > 5000
)
When run as a subquery, it returns a list of ID’s. A row is included in the result, if the outer query’s SalesPersonID is within this list. Here is the example you can try:
Read More: Using Where EXISTS in SQL >>, SQL ANY and ALL Operators>>
Subqueries in the FROM Clause
Like all subqueries, enclose subqueries within the FROM clause with parenthesis. Unlike other subqueries though, you need to alias the derived table so that your SQL can reference its results.
In this example, we’re going to select territories and their average bonuses.
SELECT TerritoryID,
AverageBonus
FROM (SELECT TerritoryID,
Avg(Bonus) AS AverageBonus
FROM Sales.SalesPerson
GROUP BY TerritoryID) AS TerritorySummary
ORDER BY AverageBonus
The subquery alias name is TerritorySummary and is highlighted in red.
Joining to a Subquery
When this query runs, the subquery is first to run and the results created. The results are then used in the FROM clause as if it were a table. When used by themselves these types of queries aren’t very fascinating; however, when used in combination with other tables they are.
Let’s add a join to our example above.
SELECT SP.TerritoryID, SP.BusinessEntityID, SP.Bonus, TerritorySummary.AverageBonus FROM (SELECT TerritoryID, AVG(Bonus) AS AverageBonus FROM Sales.SalesPerson GROUP BY TerritoryID) AS TerritorySummary INNER JOIN Sales.SalesPerson AS SP ON SP.TerritoryID = TerritorySummary.TerritoryID
Read More: What is the Difference Between a Join and Subquery?
Table Relationships with the Query
From a data modeling point of view this query looks like the following:

There is a relationship between the TerritorySummary and the joined table SalesPerson. Of course, TerritorySummary only exists as part of this SQL statement since it is derived.
By using derived tables we are able to summarize using one set of fields and report on another. In this case, we’re summarizing by TerritoryID but report by each salesperson (BusinessEntityID).
You may think you could simply replicate this query using an INNER JOIN, but you can’t as the final GROUP BY for the query would have to include BusinessEntityID, which would then throw-off the Average calculation.
Subqueries in the HAVING Clause
You can use sub queries in you SQL’s HAVING clause to filter out groups of records. Just as the WHERE clause is used to filter rows of records, the HAVING clause is used to filter groups. Because of this, it becomes very useful in filtering on aggregate values such as averages, summations, and count.
The power of using a subquery in the HAVING clause is now you don’t have to hard-code values within the comparisons. You can rely on the subquery’s results to do so for you.
For example, it is now possible to compare the average of a group to the overall average. We’ve always been able to use the average of the group in the HAVING clause, but had no way to compute the overall average. Now, using subqueries, this is possible.
In this example we’re selecting employee job titles having remaining vacation hours greater than the overall average for all employees.
Here I’ve written the query without using a subquery
SELECT JobTitle,
AVG(VacationHours) AS AverageVacationHours
FROM HumanResources.Employee
GROUP BY JobTitle
HAVING AVG(VacationHours) > 50
The subquery replaces the text highlighted in red. Now here is the complete statement including the subquery:
SELECT JobTitle,
AVG(VacationHours) AS AverageVacationHours
FROM HumanResources.Employee
GROUP BY JobTitle
HAVING AVG(VacationHours) > (SELECT AVG(VacationHours)
FROM HumanResources.Employee)
This query is executed as:
- Compute the remaining average vacation hours for all employees. (subquery)
- Group records by JobTitle and computer the average vacation hours.
- Only keep groups whose average vacation hours are greater than the overall average.
Important Points Revisited
- A subquery is just a SELECT statement inside of another.
- Enclose subqueries in parenthesis ().
- Alias subqueries in your column list to make it easier to read and reference the results.
- A subquery either returns a single value or table. Be aware of which type your query returns to ensure it works correctly in the situation.
- A subquery that returns more than one value is typically used where a list of values, such as those used in and IN operator.
- Warning! Subqueries can be very inefficient. If there are more direct means to achieve the same result, such as using an inner join, you’re better for it.
- You can nest subqueries up to thirty two levels deep on SQL server. To be honest, I can’t imagine why! I’ve see maybe four deep at most. Realistically I think you only go one or two deep.
Don’t worry, if a lot of this seems confusing at the moment. You still need to learn where the use subqueries within the SELECT statement. Once you see them in action, the above points become clearer.
Conclusion
As you can see subqueries aren’t that intimidating. The key to understanding them is understanding their role in the SQL statement. By now you know that the column list in a SELECT statement can only be one value.
It follows that a subquery used in a column list can only return one value.
In other cases, such as when being used with the IN operator, which operates on multiple values, it makes sense then that the subquery can return more than one row within the SQL.
Looking to learn more? Check out these related articles.



Leave a Reply