Use the Approximate Count Distinct function, APPROX_COUNT_DISTINCT, to return an estimate distinct count of values withing rows. It is best suited for very large tables where performance matters over precision.
The latest 2019 version of SQL Server introduced many functions to the system and enriched the database engine in order to make it work faster and more accurately. Now, you can fine-tune queries and use a variety of fresh features such as compatibility level hints, enhanced database classifications, and compression estimates.
But the feature we want to describe here is called the approximate count distinct function, i.e. APPROX_COUNT_DISTINCT. It’s a simple but highly practical function that helps users of SQL Server to complete massive dataset analyses faster without jeopardizing the accuracy of the result.
What Is Approximate Count Distinct Function?
This function returns the approximate number of unique non-null values in a group. Microsoft explains that it applies to all types of expressions except image, sql_variant, ntext, or text.
According to Microsoft, APPROX_COUNT_DISTINCT evaluates an expression for each row in a group and returns the approximate number of unique non-null values in a group. As such, the feature is supposed to enable fairly accurate aggregations when you are dealing with extremely large information units.
Approximate Count Distinct Efficiencies
Instead of wasting time on super-precise calculations, you can utilize the new function and ensure a much higher level of responsiveness. You probably figured out already that approximate count distinct is developed for big data campaigns, but let’s see when you are supposed to rely on this function:
- When your data sets contain more than a billion rows
- When your columns contain a plethora of unique values
In such circumstances, the approximate count distinct function comes in quite handy as it speeds up the process while ensuring a minor error rate of 2% within a 97% probability.
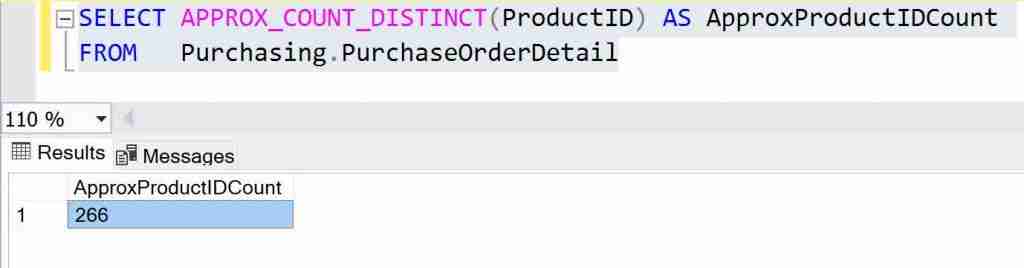
Once again, a simple example of approximate count distinct comes from Microsoft. In this case, the function gives us the rough estimation of the sum of distinct order keys from the orders table:
SELECT APPROX_COUNT_DISTINCT(ProductID) AS ApproxProductIDCount FROM Purchasing.PurchaseOrderDetail
Here are the results:
APPROX_COUNT_DISTINCT Purpose
We already mentioned what makes the APPROX_COUNT_DISTINCT function so valuable for SQL Server, but it’s important to explain it more thoroughly and discuss the reason Microsoft decided to introduce the new feature.
Namely, SQL Server is struggling to handle enormous value counts because it eats the entire memory capacity. If you’ve ever faced a data set with millions or even billions of distinct values, you know what we are talking about since the standard COUNT(DISTINCT) function sometimes takes forever to get the job done.
SQL Server is unable to process all the values in its own memory, which is why the system transfers a large portion of operations to tempdb. This sort of spilling requires a lot of additional resources and hence becomes a time-consuming process.
On the other side, the new function requires only a speck of memory capacity to calculate distinct values and come up with the approximation. Approximate count distinct is particularly useful for data sets with at least a billion unique entries.
Although it doesn’t come with ultra-precise calculations, the result is accurate enough for many SQL Server operators who want to see the results as soon as possible.
Benefits using Approximate Count Distinct
After everything we’ve stated so far, the only thing left is to clearly describe the benefits of using the approximate count distinct feature. The new SQL Server function gives you three practical advantages:
- Duration: The first and by far the most important benefit of APPROX_COUNT_DISTINCT is duration. The new function outperforms COUNT(DISTINCT) by up to 800%, but the actual time difference depends mostly on the complexity of your database. However, the fact is that approximate count distinct almost always runs much faster than the count distinct feature.
- Accuracy: Although Microsoft announced a 2% error rate, the vast majority of tests conducted by SQL Server administrators faced an even smaller error rate of 1.5% or even 1%.
- Memory footprint: Finally, the impact of APPROX_COUNT_DISTINCT is incredible. While standard value calculations can eat more than 1GB of memory, approximate count distinct will do pretty much the same work using only the slightest fraction of 1.5 KB.
The Bottom Line
The approximate count distinct feature is not going to revolutionize your SQL Server experiences, but it will certainly simplify your work and help you to complete tasks much quicker. The function proves extremely useful for massive data sets, so give it a try if you are dealing with these types of information resources.
Write a comment if you need additional explanations with APPROX_COUNT_DISTINCT and we will reply to you quickly.
Additional Resources
To learn more, check out these useful resources:



Leave a Reply