A database index allows a query to efficiently retrieve data from a database. Indexes are related to specific tables and consist of one or more keys. A table can have more than one index built from it. The keys are a fancy term for the values we want to look up in the index. The keys are based on the tables’ columns. By comparing keys to the index it is possible to find one or more database records with the same value.
It is essential the correct indexes are defined for each table, since an index drastically speeds up data retrieval. You won’t notice missing indexes for small databases. But you’ll notice your queries taking longer for larger databases.
Table of contents
The power of Database Indexes
I was once working on a database where a series of operations took about eight days to complete. By looking at the longest-running queries and running them through a query plan generator we realized the database could benefit from a new index. The optimizer estimated the query cost would drop from 300,000 operations to 30! We implemented the index and took the entire operation from eight days to two hours. Needless to say, we were very happy to get a performance boost.
Indexing within a Book
For this example consider the index in the back of a book. It’s pretty simple to use. Just scan for the subject you’re interested in, note, and flip to those pages in your book.
The keys to this index are the subject words we reference. The index entries consist of the key and page numbers. The keys are in alphabetical order, which makes really easy for us to scan the index, find an entry, note the pages, and then flip the book to the correct pages.
Consider an alternative. A book with no index may have the subject words listed at the bottom of each page. With this type of system, to find a subject you’re interested in you would have to flip through the entire book. This makes looking up subjects really slow!
Only until you got to the very end of the book would you know you have seen every page about the subject.
The power of the index is that it allows you to more or less direct access to the book’s pages you’re interested in seeing. Practically speaking, this saves hours of page-flipping!
Indexing Example Using a Deck of Cards
Consider that you have a deck of 52 cards: four suits, Ace through King. If the deck is shuffled into a random order, and I asked you to pick out the 8 of hearts, to do so you would individually flip through each card until you found it. On average you would have to go through half the deck, which is 26 cards.

Now, instead, consider that we separated the cards into four piles by suit, each pile randomly shuffled. Now if I asked you to pick out the 8 of hearts you would first select the hearts pile, which would take on average two to find, and then flip through the 13 cards.
On average it would take seven flips to find, thus nine total. This is seventeen flips (26-9) faster than just scanning the whole deck.
We could take it one step further and split the individual piles into two groups (one Ace through 6, the other 7 through King). In this case, the average search would decrease to 6.
This is the power of an index. By segregating and sorting our data on keys, we can use a piling method to drastically reduce the number of flips it takes to find our data.
B+ Trees – Index Structures Used by Databases
The structure that is used to store a database index is called a B+ Tree. A B+ Tree works similar to the card sorting strategy we talked about earlier. In a B+ Tree, the key values are separated into many smaller piles. As the name implies, the piles, technically called nodes, are connected in a tree-like fashion.
What makes a B+ Tree sizzle, is that for each pile in the tree, it is very easy and quick to do a comparison with the value you are finding and branch on to the next pile. Each pile drastically reduces the number of items you need to scan; actually exponentially so.
In this way, by walking down the nodes, doing comparisons along the way we can avoid scanning thousands of records, in just a few easy node scans. Hopefully, this diagram helps to illustrate the idea…
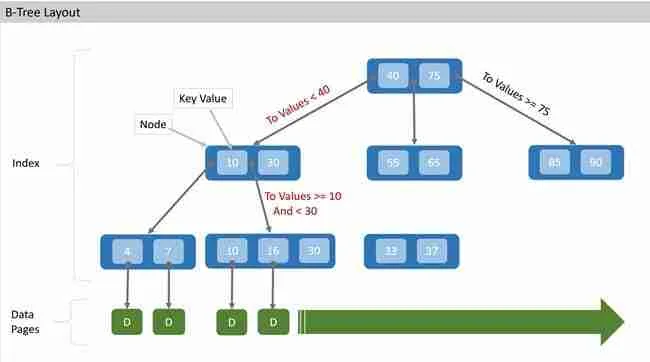
In the example above consider you need to retrieve the record corresponding to the key-value 15. To do so the following comparisons are made:
- It determined that 15 is less than 40, so we traverse the “To Values < 40” branch.
- Since 15 is greater than 10, but less than 30, we traverse the “To Values >= 10 and < 16 branch”
Power of B+ Tree Structures
With a B+ Tree Structure, it is possible to have thousands of records represented in a tree that has relatively few levels within its branches. As the number of lookups is directly related to the height of the tree, it is imperative to ensure all the branches are of equal height.
This spreads out the data across the entire tree, making it more efficient to look up data within any range.
Since data is constantly updated in a database, it’s important for the B+ Tree to keep its balance.
Each time records are added, removed, or keys updates, special algorithms shift data and key values from block to block to ensure no one part of the tree is more than one level higher than the other
Truly studying a B+ Tree is very technical and mathematical. If you are interested in the gritty detail, I would start with the Wikipedia article. I an actual example, each node (dark blue) would contain many key values (light blue). In fact, each node is the size of a block of a disk, which is traditionally the smallest amount of data that can be read from a hard drive.
This is a pretty complicated subject. I hope I’ve made it easy to understand. I would really like to know. Please leave a comment.
Read More: Database Normalization – in Easy to Understand English >>



Leave a Reply