In this article we are going to design and create a sample relational database you can use with MySql, PostgreSQL or Microsoft SQL Server. Though SQL is mostly the same within these products, I’ll be sure to point out differences so you can easily follow along using your favorite DBMS (Database Management System).
In our example, we have been asked by Lou, owner of three local pizza shops, to set up a simple database he can use to run his business.
Here are the steps we’ll go through to get our database designed:
Download the scripts and diagrams to build the databases in your favorite database engine!
Table of contents
Keep in mind that as we go through this process, I’m going to be more informal than academic. My goal is for you to understand how the design process works, and for you to see how to capture requirements, sketch out a design, and write the statements to create tables in MySql, PostgreSQL and Microsoft SQL Server
Database Design Requirements Interview
After a quick conversation with Lou to understand scope, he says the following very important statement:
I want to track my customer’s pizza orders to ensure my staff completes and delivers the best pizza. In doing so, I want to set up better tracking of my shop’s sales.
At this point let’s consider this the goal of our database. From there are several important activities we should capture:
- Customers order pizzas and either pick them up or have them delivered.
- Several shops take orders for pizzas.
- Lou tracks sales by store, date, time, and coupon.
- Pizzas are either delivered or picked up at the store.
Given this the first step is to figure out the main entities we’re working with. For now, think of entities as the “nouns” of the business. A good example of an entity is an order.
Entities eventually go on to form tables, but let’s not get ahead of ourselves.
Create Conceptual Model
The goal of the conceptual model is to help us find objects, such as orders, that we need to store within our database and how they relate to one another.
Loosely speaking you can think of model’s entities as database tables, but you’ll see, once we drill into database normalization, which doesn’t hold. Never-the-less, entities are an important step in database design. They let us put together the general framework without getting too bogged town in the detail.
Check out my article Data Modeling Principles in Action to learn more.
Here are some entities I quickly identified when looking over our requirements:
- Stores
- Employees
- Products
- Orders
- Coupons
- Deliveries
I’m sure you can think of some more. This certainly isn’t a final list, but it is a good start. Keep in mind, the goal that Lou gave us, which is to “to track my customer’s pizza orders to ensure my staff completes and delivers the best pizza. In doing so, I want to set up better tracking of my shop’s sales.”
Conceptual Model Parts
This is important, since when we’re looking at our entities, we want to make sure we don’t fall prey to scope creep. Meaning, we don’t want to design more than Lou needs into the database.
For instance, even though Employees are an entity, it doesn’t mean we need the database to keep track of Employee payroll.
Let’s now look at the entities and see how they relate to one another.
We know employees work at store. We represent this as:
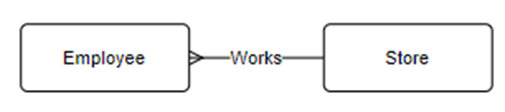
When portraying the relationship, keep in mind the  means there are one or more employees at a store and the
means there are one or more employees at a store and the  means an employee is assigned to one store.
means an employee is assigned to one store.
Also, Customer’s place orders for pizza. This is show below::

Once we put all this together, we get the following conceptual model:
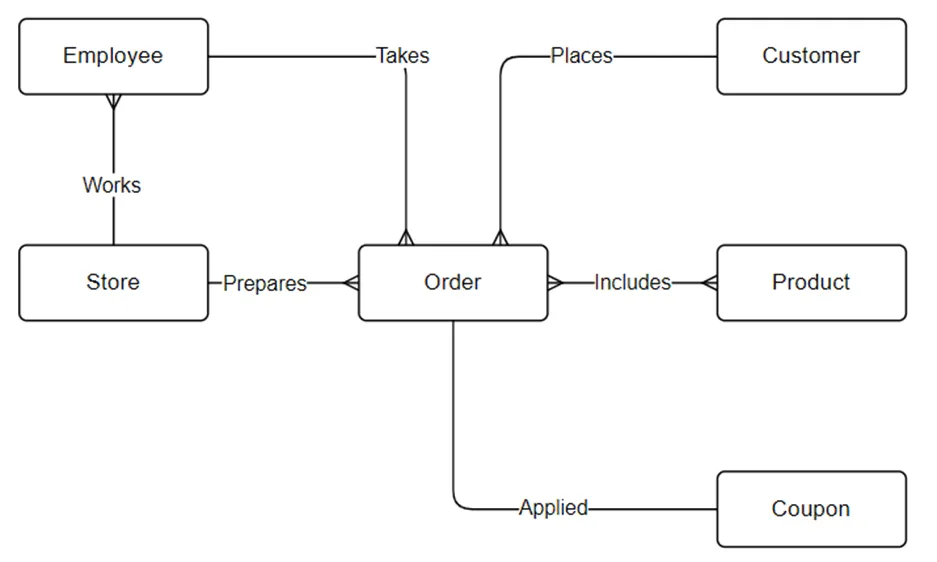
Did you notice that I left out deliveries? After further thinking, I don’t think we need to track deliveries as a separate item. It could be an attribute on the order. So, for now, to keep it simple, let’s remove it.
So far, I like what I see except for the Order to Product relationship. Notice that that is a many-to-many relationship. We’ll need to handle that later in the process with some added database design work. I think we’ll need to add a table in between the two to stand for this many-to-many relationship.
Relational Database Design and Normalization
Now that we have put together a conceptual model, let’s dig deeper and start to name the tables and columns to represent each object. As we go through this exercise, we’ll need to refine some of the table, so they are in normal form.
Having tables in normal form is a best practice and helps avoid data duplication and update issues.
If you’re not familiar with the first three normal forms, then please read Database Normalization – In Easy to Understand English.
I’ll walk you though some of the ideas as we come across them, but that article gives you the best background on normalization that I can give you today.
Let’s start designing our first table! We’ll Start with Employee.
Keep in mind we don’t need to track to much about the employee. Remember part of Lou’s goal is to “ensure my staff completes and delivers the best pizza.” That mean, we don’t need to track information to do payroll, or advanced HR functions. This is just a small business!
That said, there are a couple of key item we want to track:
- The Employee’s First and Last Name.
- What Store location they work.
- What date they started.
- The date they left our employment, if ever.
Table Design Concepts to Follow
When Designing Tables there are a couple of concepts I generally follow
- Use identity values for my primary keys. Meaning, I’ll rely on the table for generating a number to identify the row.
- I don’t usually specify the datatypes when fleshing out the diagram; we’ll do that when we script the CREATE TABLE statements.
- I’ll aim to normalize the database, but generally stop at the third normal form.
Taking in the Lou’s requirements and my design guidelines, here is the design I have for the employee table:
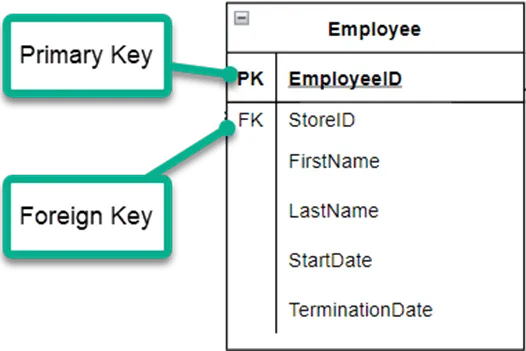
We’ll use EmployeeID as the Primary Key (PK) to identify every row. For databases that support it, we’ll set it up, so every new row automatically generates this number.
Dealing with Many to Many Relationships
Remember our conceptual model, where we showed an employee worked at a store? In this table we represent this with a Foreign Key (FK) to StoreID.
I’m expecting that the Store table’s Primary Key is StoreID.
Every employee that work for Lou is assigned to a store. In fact, they can only work at one store. This is done by adding the StoreID to their employment record.
For most of the entities form the conceptual model we’ll go through the same exercise to design the database tables. So rather than go through the model table by table, let me show you the entire model.
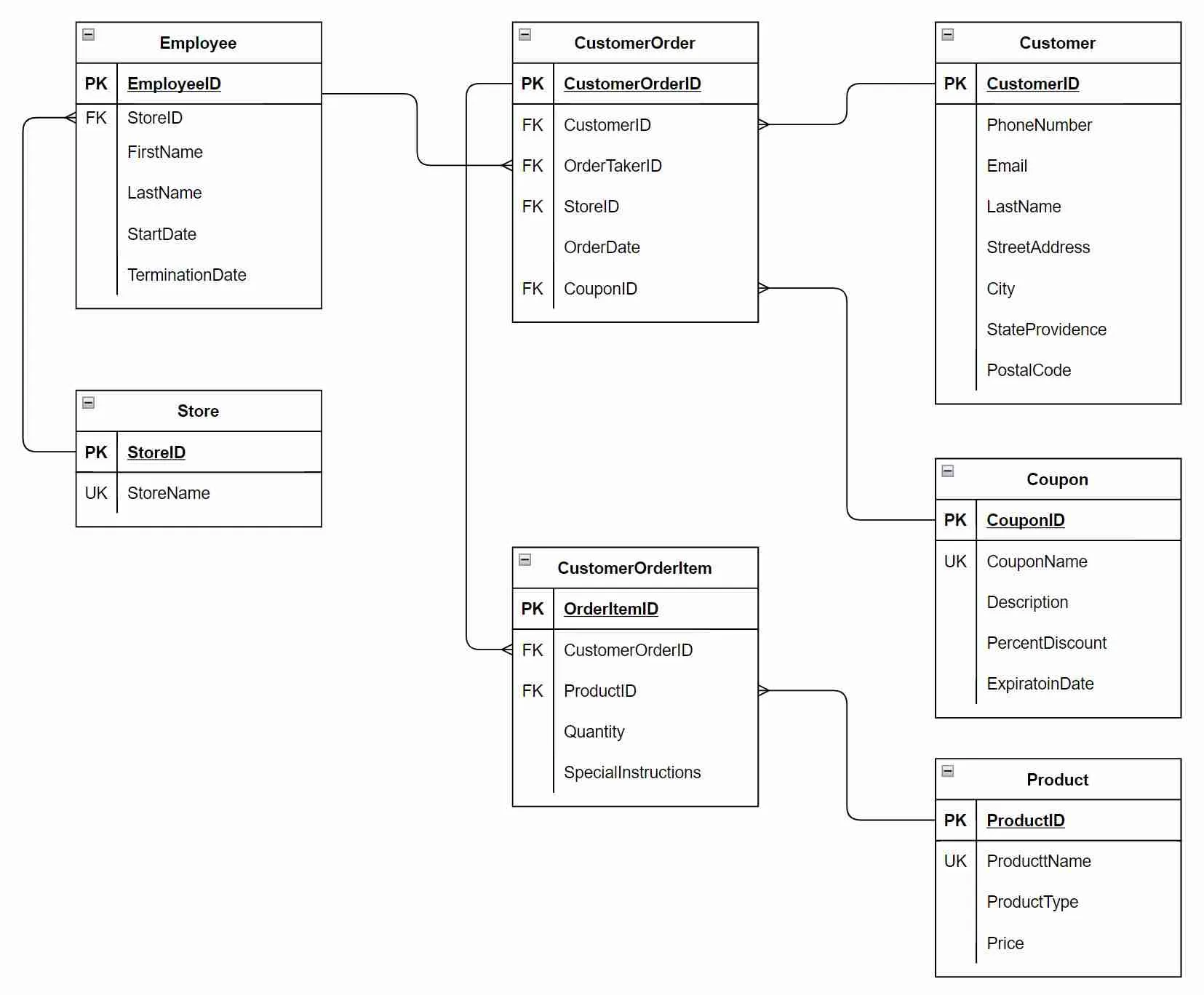
Most tables are pretty straight forward, but notice I didn’t have to do additional work on the Order entity. I didn’t leave this as just one table. The Order to Product relationship is many to many and this causes some issues with relational databases.
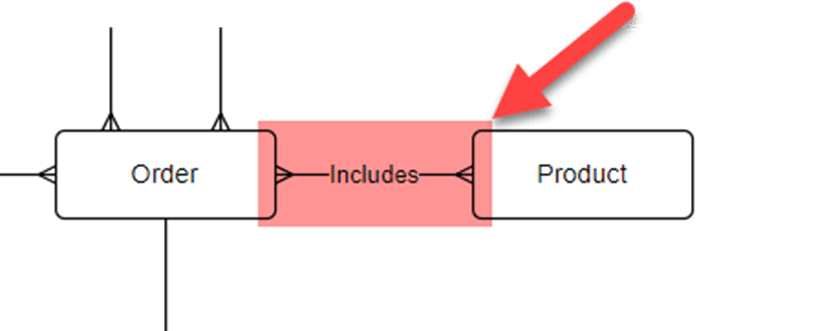
In this case it is better to break up the order to understand whether there is more to it. After some thinking, I realize an order consists of multiple item. Given this, let’s separate the Order into the Order and OrderItem. The order can capture singular information within the order, such as the customer placing the order, and we can relate one or more order items to represent the various pizzas ordered.
Three SQL Database Design Checks to Consider
Here are some quick checks to make, keeping in mind this is a simple database:
Each table needs a primary key
Each column in the table stores a single value (atomic value)
When we separated OrderItem form Orders we avoided this issue. Otherwise, we could have been left with a ProductOrder column that may have contained a value such as “Large Pizza, Chicken Wings, Personal Pan Pizza”
The columns in the tables are independent of one another
They are only dependent on the primary key. Notice that in the OrderItem table there is Total column. If it was included, then it would be dependent on Quantity and ItemPrice, breaking our design guideline.
We do break this rule with Order however. I suppose you could recalculate the entire TotalItemPrice each time, but given we don’t track prices changes within our database, this amount could shift over time, so I think it is better to calculate it, and store it.
By using keeping these principles in mind we mostly design to a normalized database practice. Of course, it does make sense to look at all the database normalization rules, to ensure our design is sound.
Database Creation and Scripts
Before I begin, keep in mind all the scripts to create the samples for MySql, PostgreSQL, and SQL Server are in GIT. Here we’ll focus on creating the Employee table.
Before we create the actual DDL (Data Definition Language) script to crate the table, let’s define the column types and whether a column requires a value for each row.
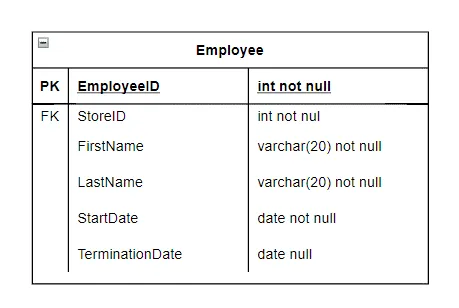
You’ll see I used some common data type to define the columns. In addition, if you see “not null” the DBMS does not allow NULL within that column, a value is needed! And a column defined as “null” can have either a value or NULL.
MySQL and PostgreSQL
CREATE TABLE Employee ( EmployeeID int not null, StoreID int not null, FirstName varchar(20) not null, LastName varchar(20) not null, StartDate date not null, TerminationDate date null, PRIMARY KEY (EmployeeID), FOREIGN KEY (StoreID) REFFERENCES Store (StoreID) )
Both MySQL and PostgreSQL are the same in this case. A bonus!
SQL Server
CREATE TABLE Employee
(
EmployeeID int not null,
StoreID int not null,
FirstName varchar(20) not null,
LastName varchar(20) not null,
StartDate date not null,
TerminationDate date null,
CONSTRAINT pkEmployeeID PRIMARY KEY (EmployeeID),
CONSTRAINT fkEmployeeStoreIDStore FOREIGN KEY
(StoreID) REFFERENCES Store (StoreID)
)
SQL Server defines constraints a bit differently. Notice that we need to use the CONSTRAINT keyword. Also, you need to name the constraint. This all seems old-school to me, but that’s the breaks.
Conculusion
Regardless of whether you’re using MySQL, PostgreSQL, or SQL Server as your DBMS, the steps to design your database are the same. Where you’ll start to see differences is when you get into the scripting. For the most part each product follows ANSI-SQL standards, but they do differ.
We see this with the table constraints! SQL Server differs the most. Luckily, the concepts are the same. So, if you focus on one DBMS at a job, and then need to switch, it won’t be much of an issue. Yes, there will be a bit of a learning curve, but not a huge one.
Related Articles



Leave a Reply