You can learn to write SQL. It isn’t hard. Yes, there are many details to mind, but none of it is impossible. In this series of articles I’ll show you the three steps I go through to write complex queries.
All the examples for this lesson are based on Microsoft SQL Server Management Studio and the AdventureWorks2012 database. You can get started using these free tools using my Guide Getting Started Using SQL Server.
Table of contents
- Introduction to Three Simple Steps to Write Better SQL
- Database Review
- Overall Structure of a Table
- Relationships
- Database Views
- Step 1 – Understand your Database Table’s Meanings and their Relationships to write SQL
- Tables
- Columns
- Keys and Relationships
- Views
- Step 2 – Pose the Question
- Step 3 – Write SQL
- Where Clause
- Order By
- Build SQL
Introduction to Three Simple Steps to Write Better SQL
Writing queries is difficult! It’s hard enough sometimes to ask another person a question and get the right answer; asking a very literal minded computer sometimes seems nearly impossible. What we say and what we mean are sometimes entirely different things.

If you understand SQL syntax, but are having a hard time formulating your queries, this article is for you. It can be frustrating knowing all the pieces of the puzzle, but not having the knowledge to complete the full picture. I think that once you go through the steps in this article series, you will gain the confidence to write SQL queries.
The goal of these articles is to help guide you through the process of writing SQL queries. The focus of the articles isn’t to teach you SQL, rather it is to help you understand how to properly pose questions into the form the database can understand.
No doubt you have worked with computers in the past and know how unyielding they are. Computers make little assumptions and have a very difficult time “filling in the gaps.” Computers don’t like ambiguity.
Part of a Database
Before we begin to write queries we’ll briefly review the parts of a database. This is important as tables, views, and relationships make up the substance of our queries. Understanding the functions of these database objects will help you recognize which set of tables and joins are relevant to your query.
In this approach to learning SQL we’ll divide the problem of writing a query into three steps:
- The first step is to pose the question. This will be in the form of a phrase.
- In the second step we’ll work toward taking our question and transforming it into a SQL statement. To do this we’ll start to map key aspects of our question into database language, such as tables and column names. In addition, we’ll map out the various relationships. To make this easy I’ll introduce you to a simple worksheet that you can use to organize your findings.
- In the third step, we’ll translate our mapped information into SQL. Here we’ll focus on syntax, gradually building up your statement, and verifying its results along the way.
Once you’re ready to complete the SQL we’ll show you how to do so gradually, making troubleshooting easier. Nothing is more frustrating than running a large SQL statement and seeing no results. By starting small, working slowly, and building on small success, we’ll work ourselves up to the complete and fully functioning answer.
Database Review
In this section we are going to review the various parts of a database. This is important as when we are writing queries we interact with various pieces of the database. We directly interact with tables and views to pull information from the databases, but what isn’t usually apparent is that we also interact with the databases’ relationships and indexes to get a feel for the meaning of tables and the dependencies between them.
A relational database is made up of several components, of which the table is most significant. The table is where all the data in a database is stored, and without tables, there would not be much use for relational databases.
Overall Structure of a Table
A database consists of one or more tables. Each table is made up of rows and columns. If you think of a table as a grid, the columns go from left to right across the grid and each entry of data is listed down as a row.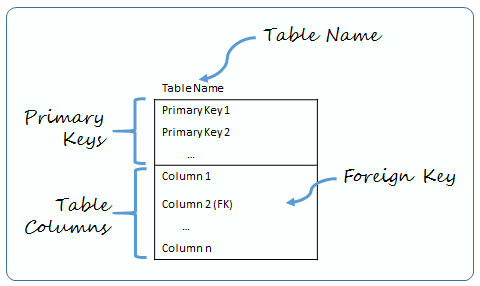
The diagram above shows my method to model a relational database table. The major elements that are depicted include:
- The Table Name, which is located at the top of the table.
- Table Columns – There can be one or more table columns. Columns hold specific types of data such as dates, numbers, or text.
- The Primary Keys. Every relational table has one primary key. Its purpose is to uniquely identify each row in the database. No two rows can have the same primary key value. The practical result of this is that you can select every single row by just knowing its primary key.
- Foreign Key – This is a column or set of columns which match a primary key in another table.
Relationships
When databases are normalized, similar information is typically split up and placed in separate tables. This could happen, for instance, if an employee has worked in several departments over the years.
Instead of listing all the departments in the employee record, a separate table is created showing the employee’s history working in various departments.
When this is the case, the tables are said to be related.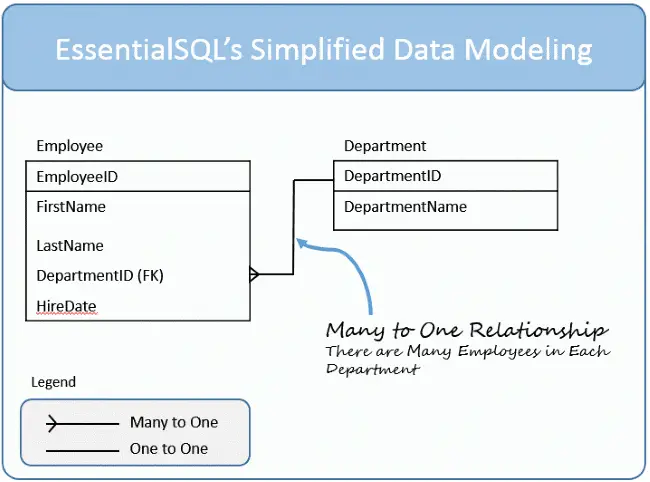
In this example the tables are related by the Employee ID.
We connect lines between tables to show relationships. In some cases an entry in one table can be related to one or more entries in another. This is called a one-to-many relationship. In our example there is one employee that has worked in many departments; therefore, we show a one-to-many relationship.
The reason this is important as it influences the number of rows returned in a query.
Database Views
A view is a searchable object in a database that is defined by a query.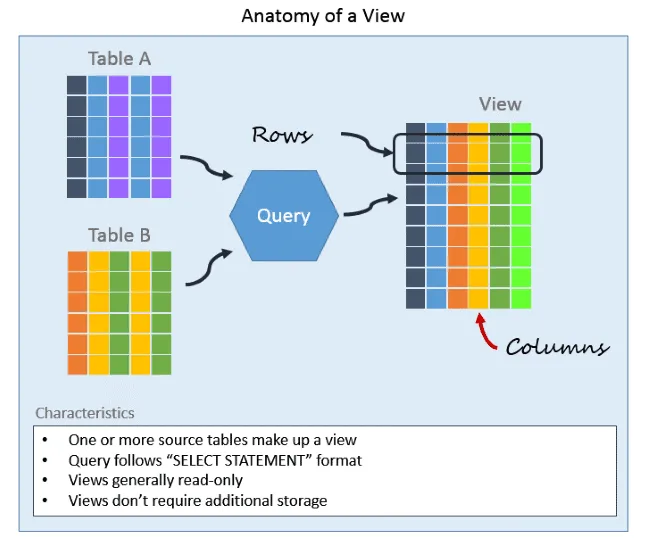
Though a view doesn’t store data, you can query a view like you can a table.
A view can combine data from two or more tables, using joins, and it can also just contain a subset of information. This makes them convenient to abstract, or hide, complicated queries.
Step 1 – Understand your Database Table’s Meanings and their Relationships to write SQL
Understanding your database is more than just knowing it is built with tables, views, and relationships. In order to write meaningful queries you need to understand how real world data was decoded and stored in the database.
These major components provide clues we can use to translate real-world requests into actionable database queries. From understanding what content is contained within a table to understanding how to relate one table to another, knowing the database’s basic structure is key to creating queries.
Tables
When constructing queries it is important to understand a table’s purpose or subject. Is the table used to organize employee data or a list of classes taken? In general you can think of most tables as covering a subject, such as employees or classes.
Before writing a query look over your database’s table names. In many cases the names reveal the main topic or subjects of the tables. If you are looking for employees, then chances are the table will be named something akin to “Employee.”
What are some of the main topics captured in this excerpt of tables from the Adventureworks2012 database?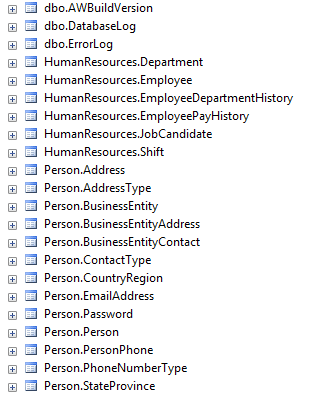
Just by reading the names you can see this database contains information about people and their jobs.
When I confronted in creating a query, I first rely on the table names to get my bearings. Usually I’ll notice tables that have promising names. To confirm if I’m on the right track, I’ll inspect their definition and look at their columns.
You’ll also find related tables in the same manner. A record of Employee Salaries may be in a table called EmployeeSalaries or EmpSal. Keep in mind that some programmers really like to abbreviate.
Developers may follow a naming convention. Here are some naming conventions. Be on the lookout for them, as they can hint towards a table’s purpose:
- Tables containing information relating to the same topic usually start with that subject’s name. Employee, EmployeeDepartmentHistory, and EmployeePayHistory are excellent examples.
- Table Prefixes, such as “Log” in the table name ErrorLog provide clues to a table purpose. Some common prefixes are: log, index, type, and code.
- Tables containing two subjects, such as EmployeeDepartmentHistory, indicate a table could be a bridge table (See Keys and Relationships).
Columns
A table’s columns give you a lot of information. Hopefully the designer gave the column a readable name. If so, then it is pretty easy to understand each column’s purpose. Listed below is the Employee table. Can you tell which column is used to store the date a person was born?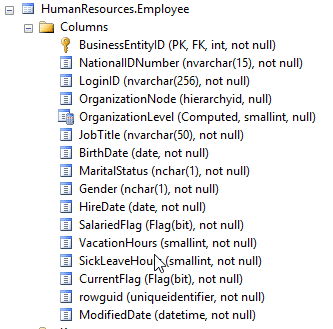
Of course! It is the column entitled BirthDate.
The column’s data type also gives you hints. In this table you can see BirthDate is a date column and can’t be null. That means, the column won’t hold numbers or text, just dates, so we’ll be able to use more advanced logic like finding birthdays 30 days from now and that the column will always have a value.
Here are some great tips you can use to learn more about columns:
- If a column is not null, it will always have a value.
- If you don’t know what values are in a column, you can select distinct values from the column to get a quick overview of all values. For instance, you can quickly find all the possible job titles in the Employee database by running the query
SELECT DISTINCT JobTitle FROM HumanResources.Employee
- Knowing if a field contains numeric or character data can help infer meaning. If a field named “WaitTime” is of character data type, then you may expect to find values such as “Long,” “Normal,” “None;” whereas, if it is numeric then WaitTime most likely represents some quantity of time such as hours, minutes, or seconds.
- Pay Attention to Naming Conventions. Many programmers add suffixes to their column names.
- columnID – This column is used to identify a row in this table or another. It is potentially a primary or foreign key (see below).
- columnNo – This field is some sort of number, perhaps an account number (e.g. AccountNo)
- columnNum – Another variant for number.
- Columns are usually CamelCasedInSQL. This is done to avoid having placing spaces in the column name, yet make the columns readable. Compare “AccountNumber” to “Account Number.”
- columnFlag – This is programmer jargon for On and Off or Yes and No.
- columnGUID – GUID stands for Globally Unique ID.

Keys and Relationships
In our example we talked about finding all the departments that an employee has worked in. By inspecting the table names it seems logical that we would want to look at the Employee and Department tables, but how are they related?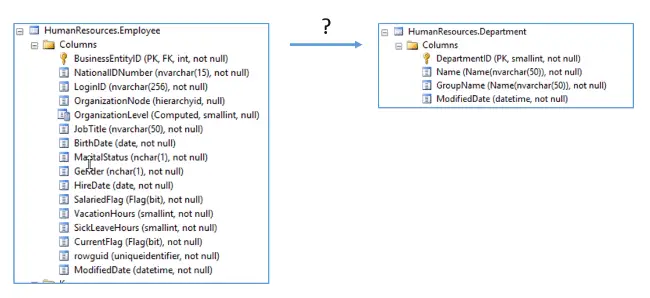
This is where it makes sense to review the relevant table’s primary keys to understand what values are used to identify the tables and to see if you can use foreign keys from other tables to make a relation.
Typically column names in tables are named the same. If the primary key is HardwareID in one table, and you know it is related, then a good start is to look for HardwareID in another table.
Check out the employee and Department Tables. How are they related?
First look at the Department table and identify the primary key. You’ll quickly see that it is named DepartmentID. Now go to the Employee table and look to see if that column or one similarly named is listed? Do you see a DepartmentID or DeptID column listed? Nope!
To me that is a huge hint. We have two islands of information and need a bridge to get between them. This is a common problem with writing SQL. Often we find the tables that contain the end results, but fail to initially find those that bridge the gap. Further digging is needed.
In our case, we are lucky that there are other tables that have employee in their name. If you look at the above database list you’ll see there is one named EmployeeDepartmentHistory. Here is a picture of all three tables: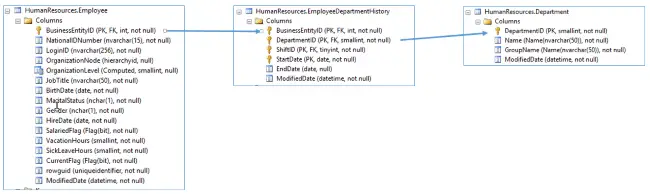
EmployeeDepartmentHistory is commonly called a junction or bridge table as it contains information from an intersection of both Employee and Departments. These types of tables used to model many to many relationships (e.g. Many Employees work in One Department, and One Employee could have work in Many Department over his career).
By reading this, I now understand the EmployeeDepartmentHistory table is going to contain employees and the departments they worked in.
Sometimes a database designer will define foreign key relationships. Foreign key relationships are used to ensure that a foreign key value exists as a primary key in another table. For instance in our database there is a foreign key relationship on EmployeeDepartmentHistory ensuring DepartmentID is only assigned values found in the Department table.
Foreign key relationships are mainly put in place to ensure data integrity, but we can also use them to confirm the database designer intentions. What tables did they mean to relate to one another?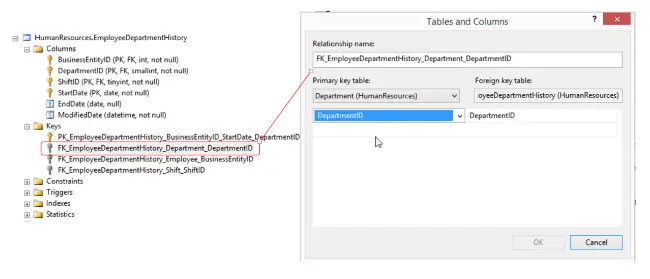
Views
Views are a fancy way of saying shortcut! When I‘m writing queries I always look for views to see whether I can use them in my queries. If a view doesn’t give you all the columns you need you have two choices:
- Use the view in a query and join to other table to get the column you want.
- Look at the view’s definition and then copy that code into your query.
Unless the view covers all the columns I need, I typically don’t use option one. Going that route can cause your code to become inefficient and hard to read. This is especially so when you have views that refer to views. The SQL quickly becomes a tangled skein.
I typically look at the view’s definition, which is easy to do and then use that code as a starting point for my own queries.
Below you can see how I opened up the view definition for vEmployeeDepartmentHistory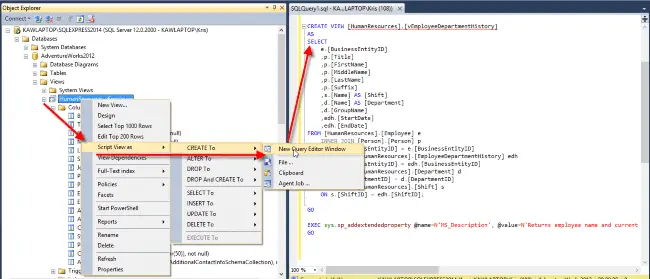
Here is the select statement from that view. As you can see, it provides great hints on how employees and department are related.
SELECT e.[BusinessEntityID], p.[Title], p.[FirstName], p.[MiddleName], p.[LastName], p.[Suffix], s.[Name] AS [Shift], d.[Name] AS [Department], d.[GroupName], edh.[StartDate], edh.[EndDate] FROM [HumanResources].[Employee] AS e INNER JOIN [Person].[Person] AS p ON p.[BusinessEntityID] = e.[BusinessEntityID] INNER JOIN [HumanResources].[EmployeeDepartmentHistory] AS edh ON e.[BusinessEntityID] = edh.[BusinessEntityID] INNER JOIN [HumanResources].[Department] AS d ON edh.[DepartmentID] = d.[DepartmentID] INNER JOIN [HumanResources].[Shift] AS s ON s.[ShiftID] = edh.[ShiftID]
From this view you can see Employee is related to Department via the EmployeeDepartmentHistory table. When I see relations I can use, I’ll just copy those portions of the join statement into my own SQL.
Step 2 – Pose the Question
Before you start writing SQL, write down the question you are trying to answer. I find when I’m having a tough time trying to formulate SQL that writing down a description really helps. Unless the problem is clearly defined, it is hard for me to know how to approach it and find a solution.
Many times we take the problem definition to be a given, but often there is more than meets the eye. For example, let’s assume the question being asked is:
Which departments have employees who worked in the company more than five years?
A couple of questions come to mind:
- Are we asking for employees that have worked in a department more than five years, or is it five years total in the company?
- Are we going to include the time an employee could have been a contract employee?
- If a person leaves and then rejoins the company, how is that tracked?
- Are we looking for a list of department those employees with more than five years tenure?
As you can see, even a simple question can generate all sorts of questions and assumptions. Because of this, be very explicit when writing the question. Here is a better example:
What are the all the departments an employee has worked in while being employed by the company for five or more years?
Assumptions:
- Don’t count time the employee was a contractor
- Only include full time employees
Sometimes I find it easier to write the SQL request as a statement rather than a question.
To me “List all fulltime employees first and last names” is more intuitive than “What are the first and last names of all full time employees?”
In either case it is important you understand the goal of the question or statement. What are the results you seek to acquire? If you don’t know the goal you won’t know how to pose the question.
Write out your statement in simple English.
Be succinct, if you get too wordy, your statement will be hard to understand. The idea is that as we formulate the statement’s key elements required for the SQL statement will reveal themselves.
When writing the question or statement speak in the language of your database.
If people are employees, then pose your questions as “which employees are given raises?” instead of “which people are given raises”.
Here are some examples of questions and statements you could ask and how they could be improved:
Example 1
OK: Who is married and takes accounting?
Better: Which employees are married and have taken accounting as a training class?
What is it better? By being more clear on what “takes accounting” means, we are being clear we are looking for employees who took accounting in one of the company’s training classes rather than, say, at a community college.
Example 2
OK: List past due accounts
Better: List customer accounts that have a balance due and haven’t made a payment in the last 30 days?
What is better? We are defining the criteria for what it means for an account to be past due.
Example 3
OK: What customer are we late in shipping parts?
Better: What customers have an order whose order date was five days ago and have no shipment date?
Step 3 – Write SQL
Now that you have your goal defined in terms of a good question it is time to start to hone in on the specifics. To do this we are going to work through the general structure of SQL:
- Select List – What columns do we want to include in our query?
- Join Conditions – What tables are needed to display those columns? Are other tables, such as bridge tables required to “navigate” to those tables?
- Where Clause – Are there any filter conditions we want to consider? Are the columns we want to filter included in the list of tables? If not, we’ll have to include them in the join conditions.
- Order by – How should the results be sorted?
As we work through the structure, we aren’t going to focus on the actual SQL syntax. That will come later. The goal is to start to identify and collect all the pieces we’ll need to put the puzzle together. We’ll use the SQL Coding Worksheet found in Appendix A.
You will see that it isn’t really hard to fill out one portion of the sheet, and once it is filled out, it is really easy to write the SQL. The worksheet’s secret is that it helps us break down a seemingly complicated problem into it simple parts.
For this section we’ll use the request “List married Employees by name and the departments they have worked in.”
To make our query useful to read we need to specify what columns we want to see. I usually list them along with the table they are found in. For our example we would want to know the Employee Number, Employee Name, Department Name, Date the Employee Started in the Department, and what shift they worked.
Select List
We’ll start by finding the required columns in the Employee Table. There we find the NationalID, but no names! Where are they located?
If you review the EmployeeTable in Microsoft SQL Studio you see there is a foreign key defined on Employee. This “points to” the Person table. That is our hint.
Once you view the Person table’s columns, you see there are First and Last Names.
So far, here is our list:
As you continue to inspect table names and their foreign keys, you eventually happen across the Department and EmployeeDepartmentHistory tables. From here we obtain the remaining columns from our list.
Here is the final list: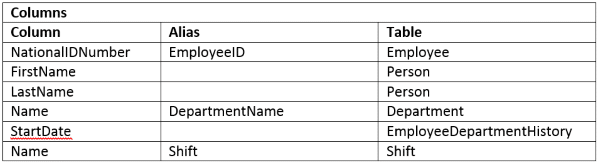
You’ll see I added Aliases for some of the columns and I did so to help differentiate them from similarly named columns in other tables.
Join Conditions
Now that we have identified the columns to display and their source tables, it is time to understand how these tables are related to one another. Usually I do this step at the same time I’m identifying the columns, but it is easier to explain it as a separate step.
Here is what I do.
First, as I’m identifying the columns and tables, I keep a separate note of the tables used and how they are related. If it gets too overwhelming I’ll draw a simple picture to help me visualize the interconnections.
Usually once I’m done identifying the columns I’ll end up with a list as so:
This is a pretty good start, but there is one relationship missing.
If you look you’ll see there is no start and end between the Employee and EmployeeHistory table. This brings up a really good reason why I like to create diagrams when I can keep it all straight in my head. If you diagram this out, all the tables should be listed on the page and chained together.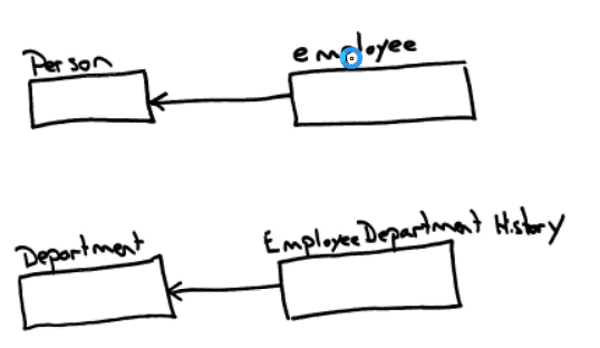
A warning flag should go up if the chain isn’t complete. In this diagram you’ll notice there is no relationship between Employee and EmployeeDepartmentHistory.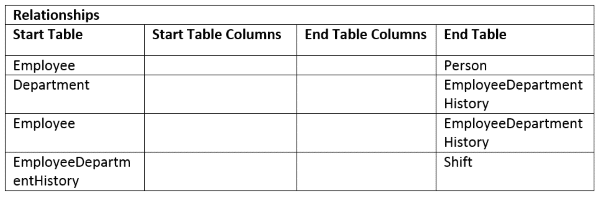
Once the relationships are identified it is time to understand how the tables are exactly linked. Here are the ticks I use to quickly identify the correct columns:
- Are there similarly named columns in both tables? If you have two tables, Order and OrderDetail, and both tables have a column named OrderID, chances are that column is used to relate the tables together.
- Is one of the columns a Primary Key in its table? Finding the set of columns which identifies the primary key is important. This set, one or more columns, will show up in other tables as foreign keys. This is important as primary key and foreign key pairs form the relationships we are seeking.
Let try to use these to identify the columns used in our table’s relationship.
Employee table
When identifying the relationship between the Employee and Person table, the first thing I noticed was that each table had a column name BusinessEntityID. The column was a primary key in both tables. This led me to infer this column is used to relate the two tables together. I confirmed this by reviewing the table’s keys. In the Employee table I found a definition named FK_Employee_Person_BusinessEntityID. Just by reading the name I assumed I nailed the relationship, but I opened the definition to be safe and was able to confirm my hunch.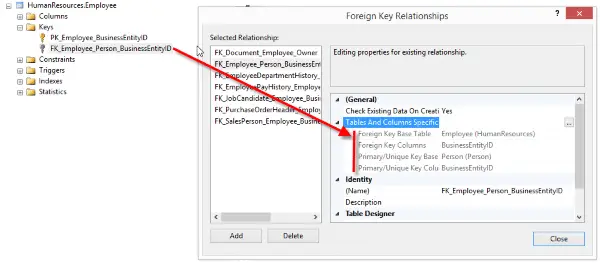
Result: The Employee table is related to the Person table by BusinessEntityID. Since both columns are primary keys, there is a one-to-one relationship between the tables.
Department
The next table in our list is the Department table. We already know this table is related to the EmployeeDepartmentHistory table, but how?
Again, let look at the columns and make some inferences. I think it is easiest to explain this one visually. I opened Microsoft SQL Studio and navigated to the Department and EmployeeDepartmentHistory tables and expanded their columns folders. This is what I saw: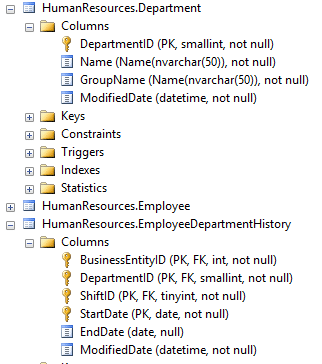
What immediately jumped out was that Department table’s primary key appears in both tables.
Being it is a foreign key (FK) in EmployeeDepartmentHistory, I’m sure DepartmentID relates the tables. I confirmed this by looking at the Keys definition.
Result: Department and EmployeeDepartmentHistory are related by the DepartmentID. And since DepartmentID is the primary key in the Department table, we can be sure there is a one to many relationship from Department to EmployeeDepartmentHistory.
Employee (revisited)
The third entry in our list represents the relationship between the Employee table and EmployeeDepartmentHistory.
Using the same techniques we determine the BusinessEntityID is the column relating both tables together.
Here is what our table of relations looks like: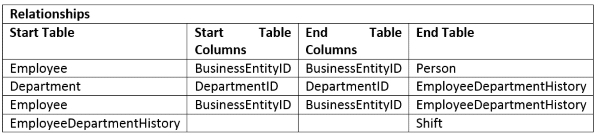
Now let’s look to see whether we have to filter any records.
Where Clause
In our statement we said we wanted to “List married Employees…” Most filters are made by comparing column values. Our challenge then, is to find the column and appropriate value to compare.
Since we are talking about marital status, and that’s a property that deals with people, I’ll focus my efforts to the Person and Employee tables.
When I look at the Person table in the explorer I don’t see any relevant columns; however, when I look at the Employee table one field stands out: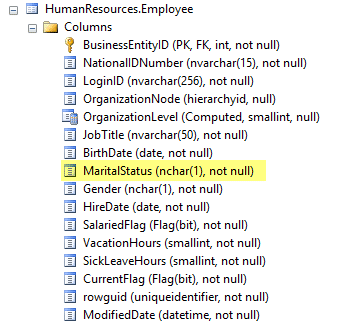
Now we know the column name, but what is the value for MaritalStatus? I think I could guess…
It is either “Y” for married and “N” for single or “M” for married and “S” for single, but until I look at the data I won’t know. My trick is look at the table’s distinct values as shown below: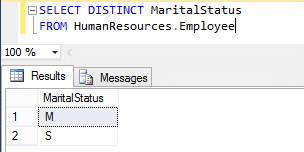
Base on this we can infer ‘M’ is used to indicate someone is married.
Order By
The final item to sort out (no pun intended) is to figure out how to order our results. If you recall, in our original statement we wanted to sort the items by employee name. Let be specific and say we want to sort by last name and then first. Base on this, we can fill out the sort section as:
Our worksheet in final form looks like the following: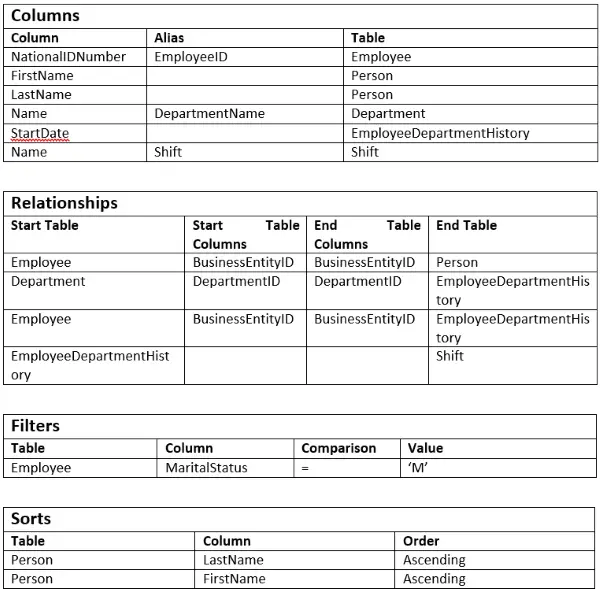
Build SQL
When working on complicated queries I like to write them in stages. I find that it can be really hard to debug a really complex query. Instead, I like to write a piece, test it, make sure it runs, and then build on that success. Working this way makes it easy to know whether what I just wrote is causing the query to break.
Another strategy I use to start at one end of the query and work towards the other. What I mean is that I think of the related tables strung out in a line and work from the left to the right. In our example, you could use the sketch as a guide as so:
Person à Employee à EmployeeDepartmentHistory à Department
Let’s start with the person table then.
Looking at our worksheet we can see the name comes the person table. Our query starts as
SELECT Person.LastName,
Person.FirstName
FROM Person.PersonAlso notice we wanted our query to be sorted by Last, and then First Name. Our query now becomes:
SELECT Person.LastName,
Person.FirstName
FROM Person.Person
ORDER BY Person.LastName, Person.FirstNameAt this point we need to move on to the Employee table. In order to access columns from this table in a meaningful way we need to create a join between Person and Employee. Looking at our chart, we see these two tables are joined by BusinessEntityID. Since we only want to include rows from both table when there is a match on BusinessEntityID, we’ll use an INNER JOIN.
Our SQL now looks like
SELECT Person.FirstName
FROM Person.Person
INNER JOIN HumanResources.Employee
ON Person.BusinessEntityID = Employee.BusinessEntityID
ORDER BY Person.LastName, Person.FirstNameNow that we have access to the Employee columns, we can add our filter for the Martial status.
WHERE Employee.MaritalStatus = 'M'
Now we add the join for EmployeeDepartmentHistory.
INNER JOIN HumanResources.EmployeeDepartmentHistory On Employee.BusinessEntityID = EmployeeDepartmentHistory.BusinessEntityID
Continuing on to the Department table, we add that relation. Looking at the chart we see that EmployeeDepartmentHistory is related to Department by the DepartmentID. Once these tables are related we can add the department name. Here is the completed query.
SELECT Person.LastName,
Person.FirstName,
Department.Name AS DepartmentName
FROM Person.Person
INNER JOIN
HumanResources.Employee
ON Person.BusinessEntityID = Employee.BusinessEntityID
INNER JOIN
HumanResources.EmployeeDepartmentHistory
ON Employee.BusinessEntityID = EmployeeDepartmentHistory.BusinessEntityID
INNER JOIN
HumanResources.Department
ON EmployeeDepartmentHistory.DepartmentID = Department.DepartmentID
WHERE Employee.MaritalStatus = 'M'
ORDER BY Person.LastName, Person.FirstName;I know this may seem like a lot to remember, but one you get the hang of writing SQL statements it becomes second nature. I don’t need to use the work sheet anymore, but in the beginning it was really great help. I used it to organize my thought and to piece together which tables and relations were required to complete my query.



Leave a Reply