In this article find out how to find duplicate values in a table or view using SQL. We’ll go step by step through the process. We’ll start with a simple problem, slowly build up the SQL, until we achieve the end result.
By the end you’ll understand the pattern used to identify duplicate values and be able to use in in your database.
All the examples for this lesson are based on Microsoft SQL Server Management Studio and the AdventureWorks2012 database. You can get started using these free tools using my Guide Getting Started Using SQL Server.
Find Duplicate Values in SQL Server
Let’s get started. We’ll base this article on a real-world request; the human resource manager would like you to find all employees sharing the same birthday. She would like the list sorted by BirthDate and EmployeeName.
After looking at the database it becomes apparent the HumanResources.Employee table is the one to use as it contains employee birthdates.
At first glance it seem like it would be pretty easy to find duplicate values in SQL server. After all we can easily sort the data.
But once the data is sorted it gets harder! Since SQL is a set based language, there is not an easy way, except for using cursors, to know the previous record’s values.
If we knew these, we could just compare values, and when they were the same flag the records as duplicates.
Luckily there is another way for us to do this. We’ll use an INNER JOIN to match employee birthdays. By doing so, we’ll get a list of employees sharing the same birthdate.
This is going to be a build-as you go article. I’ll start out with a simple query, show results, and point out what needs refinement and move on. We’ll start out with getting a list of employees and their birthdates.
Step 1 – Get a List of Employees Sorted By Birthdate
When working with SQL, especially in uncharted territory, I feel it is better to build a statement in small steps, verifying results as you go, rather than writing the “final” SQL in one step, to only find I need to troubleshoot it.
Hint: If you’re working with a very large database, then it may make sense to make a smaller copy as your dev or test version and use that to write your queries. That way you don’t kill the production database’s performance and get everyone down on you.
So for our first step, we are going to list all employees. To do so,we’ll join the Employee table to the Person table to so we can get the employee’s name.
Here is the query so far
SELECT E1.BusinessEntityID,
P.FirstName + ' ' + p.LastName AS FullName,
E1.BirthDate
FROM HumanResources.Employee AS E1
INNER JOIN
Person.Person AS P
ON P.BusinessEntityID = E1.BusinessEntityID
ORDER BY E1.BirthDate, FullName
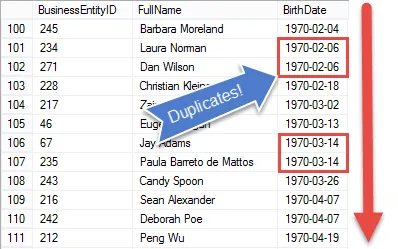
If you look at the result you see we have all the elements of the HR manager’s request, except that we’re displaying every employee
In the next step we’ll set up the results so we can start to compare birth dates to find duplicate values.
STEP 2 – Compare Birthdates to Identify Duplicates.
Now that we have a list of employees we now need a means to compare birthdates so we can identify employees with the same birthdates. In general these are duplicate values.
To do the comparison we’ll do a self-join on the employee table. A self-join is just a simplified version of an INNER JOIN. We start out using BirthDate as our join condition. This ensures we’re only retrieving employees with the same birth date.
SELECT E1.BusinessEntityID,
E2.BusinessEntityID,
P.FirstName + ' ' + p.LastName AS FullName,
E1.BirthDate
FROM HumanResources.Employee AS E1
INNER JOIN
Person.Person AS P
ON P.BusinessEntityID = E1.BusinessEntityID
INNER JOIN
HumanResources.Employee AS E2
ON E2.BirthDate = E1.BirthDate
ORDER BY E1.BirthDate, FullName
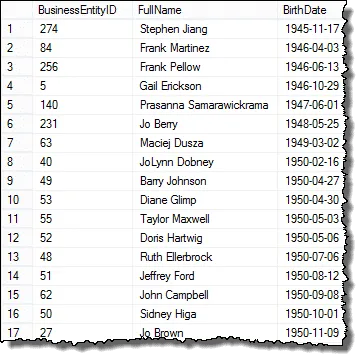
I added E2.BusinessEntityID to the query so you can compare the primary key from both E1 and E2. You see in many cases that they are the same.
The reason we’re focusing on BusinessEntityID is that it is the primary key and the unique identifier for the table. It becomes a highly concise and convenient means to identify a row’s results and to understand its source.
We’re getting closer to obtaining our final result, but once you check out the results you’ll see we’re picking up the same record in both the E1 and E2 match.
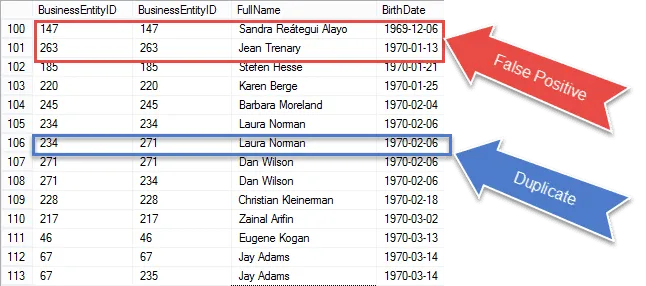
Check out the items circled in red. Those are the false positives we need to eliminate from our results. Those are the same rows matching to themselves.
The good news is we are really close to just identifying the duplicates.
I circled a 100% guaranteed duplicate in blue. Notice that the BusinessEntityID’s are different. This indicates the self-join is matching BirthDate on different rows – true duplicates to be sure.
In the next step we’ll take those false positives head on and remove them from our results.
Step 3 – Eliminate Matches to Same Row – Remove False Positives
In the prior step you may have noticed all the false positive matches have the same BusinessEntityID; whereas, the true duplicates were not equal.
This is our big hint.
If we want to only see duplicates, then we need to only bring back matches from the join where the BusinessEntityID values are not equal.
To do this we can add
E2.BusinessEntityID <> E1.BusinessEntityID
As a join condition to our self-join. I’ve colored the added condition in red.
SELECT E1.BusinessEntityID,
E2.BusinessEntityID,
P.FirstName + ' ' + p.LastName AS FullName,
E1.BirthDate
FROM HumanResources.Employee AS E1
INNER JOIN
Person.Person AS P
ON P.BusinessEntityID = E1.BusinessEntityID
INNER JOIN
HumanResources.Employee AS E2
ON E2.BirthDate = E1.BirthDate
AND E2.BusinessEntityID <> E1.BusinessEntityID
ORDER BY E1.BirthDate, FullName
Once this query is run you’ll see there are fewer rows in the results, and those which remain are truly duplicates.
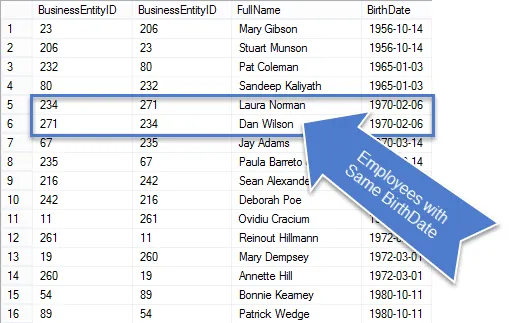
Since this was a business request, let’s clean up the query so we are only showing the information requested.
Step 4 – Final Touches
Let’s get rid of the BusinessEntityID values from the query. They were there only to help us troubleshoot.
The final query is listed here
SELECT P.FirstName + ' ' + p.LastName AS FullName,
E1.BirthDate
FROM HumanResources.Employee AS E1
INNER JOIN
Person.Person AS P
ON P.BusinessEntityID = E1.BusinessEntityID
INNER JOIN
HumanResources.Employee AS E2
ON E2.BirthDate = E1.BirthDate
AND E2.BusinessEntityID <> E1.BusinessEntityID
ORDER BY E1.BirthDate, FullName
And here are the results you can present to the HR Manager!
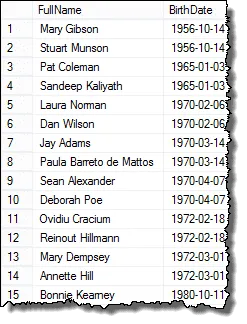
Mark, one of my readers, pointed out to me that if there are three employees that have the same birth dates, then you would have duplicates in the final results. I verified this and that is true. To return a list show each duplicate only once, you can use the DISTINCT clause. This query work in all cases:
SELECT DISTINCT P.FirstName + ' ' + p.LastName AS FullName,
E1.BirthDate
FROM HumanResources.Employee AS E1
INNER JOIN
Person.Person AS P
ON P.BusinessEntityID = E1.BusinessEntityID
INNER JOIN
HumanResources.Employee AS E2
ON E2.BirthDate = E1.BirthDate
AND E2.BusinessEntityID <> E1.BusinessEntityID
ORDER BY E1.BirthDate, FullName
Final Comments
To summarize here are the steps we took to identify duplicate data in our table.
- We first created a query of the data we want to view. In our example this was the employee and their birth date.
- We performed a self-join, INNER JOIN on same table in geek speak, and using the field we deemed a duplicated. In our case we wanted to find duplicate birthdays.
- Finally we eliminated matches to the same row by excluding rows where the primary keys were the same.
By taking a step by step approach you can see we took a lot of the guess work out of creating the query.
If you’re looking to improve how you write your queries or are just confounded by it all and looking for a way to clear the fog, then may I suggest my guide Three Steps to Better SQL.
Related Articles
SQL Joins – The Ultimate Guide
Remove Duplicates Using Window Functions



Leave a Reply