Use the DELETE statement to remove rows from a SQL Server data table. In this article we’ll explore how to use the DELETE statement. We discuss some best practices, limitations, and wrap-up with several examples.
This is the fourth article in a series of articles. You can start at the beginning by reading Introduction to SQL Server Data Modification Statements.
All the examples for this lesson are based on Microsoft SQL Server Management Studio and the AdventureWorks2012 database.
Table of contents
Before we Begin
Though this article uses the AdventureWorks database for its examples, I’ve decided to create an example table for use within the database to help better illustrate the examples. You can find the script you’ll need to run here.
Also, let’s initially populate the table with some data using the following INSERT statement:
WITH topSalesPerson (FullName, SalesLastYear, City, rowguid)
AS (
SELECT S.FirstName + ' ' + S.LastName, S.SalesLastYear, S.City ,NEWID()
FROM Sales.vSalesPerson S
WHERE S.SalesLastYear > 1000000
)
INSERT INTO esqlSalesPerson (FullName, SalesLastYear, City, rowguid)
SELECT FullName, SalesLastYear, City, rowguid
FROM topSalesPerson
You can learn more about the INSERT statement by reading our article Introduction to the INSERT Statement.
Basic Structure of the DELETE Statement
The DELETE statement removes rows from a database table. There are three components to an DELETE statement:
- The table you wish to remove rows from.
- The criteria used to choose the rows to remove.
The general format for the DELECT Statement is:
DELETE FROM tableName WHERE searchCondition …
We’re now going to do some sample DELETEs, so if you haven’t done so already, run the script to create the esqlSalesPerson table.
Examples using DELETE
Simple Example – Deleting Every Row
When you use DELETE without a WHERE clause, it removes every row from the table. If we want to delete every from esqlSalesPerson we could run:
DELETE FROM esqlSalesPerson
I would recommend, for the purposes of our example, to wrap the DELETE command in a transaction so you don’t have to repeatedly insert rows into the example database. Here you’ll see the same DELETE statement.
BEGIN TRANSACTION SELECT COUNT(1) FROM esqlSalesPerson DELETE FROM esqlSalesPerson SELECT COUNT(1) FROM esqlSalesPerson ROLLBACK
The first count statement return 13 rows; whereas, the second returns 0. Since I ROLLBACK the transaction, the delete operation isn’t permanent.
Simple Example – Deleting A Single Row
A more realistic use case it deleting a single row. In many applications, this a achieved by filtering on a single row.
If you know the primary key, you’re golden, as the primary key is unique and meant to positively identify each row.

Suppose we want to delete Jillian Carson’s row. To do so we would issue the following:
DELETE FROM esqlSalesPerson WHERE SalesPersonID = 10095
You may be wondering how you would know the primary key.
You can imagine if you had a web app that listed every sales person, that the grid may contain the sales person’s Full Name, and Last Year’s Sales, but hidden on the grid would also be their SalesPersonID.
When a user selected a row on the grid, and elected to remove the row, the application would retrieve the hidden primary key for the row, and then issue the delete command to the database.
Simple Example – Deleting Multiple Rows
Suppose we only want to show high performing sales people in the esqlSalesPerson table. We only want to keep those sales people with last year’s sales greater or equal to $2,000,000.
Since our table contain those with less than this amount, we need to remove them by running the following:
DELETE FROM esqlSalesPerson WHERE SalesLastYear > 2000000.00
You can run the following command to try the script within a transaction:
BEGIN TRANSACTION SELECT COUNT(1) FROM esqlSalesPerson DELETE FROM esqlSalesPerson WHERE SalesLastYear < 2000000.00 SELECT FullName, SalesLastYear FROM esqlSalesPerson ROLLBACK
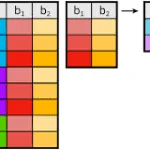
Here are the result of running the script:

The blue arrow shows there were originally 13 records, and the red the remaining whose sales are greater than or equal to two million dollars.
You can also create more complex filtering conditions. Later on in the article we’ll show how to use a subquery. You can also use Boolean conditions, in the WHERE clause as well just as you would with the SELECT statement.
Considerations using the DELETE Statement
To delete all rows in a table, use TRUNCATE TABLE. It is much fast than DELETE as it does log changes. But there are key differences (See DELETE isn’t TRUNCATE! below)
Also, don’t forget you can use the @@ROWCOUNT function to find out how many rows were deleted.
Error handling
If a DELETE statement throw an error all rows are restored to their state prior to the statement being run. If an error is triggered no rows are removed.
There are many reasons why a delete statement may fail. Some of the more typical ones include:
- Orphan Rows – if a FOREIGN KEY constraint is defined between two tables, such as parentTable and childTable, then DELETE a parentTable row will cause an error if childTable rows related to the parent exist. They way around this is to first remove the corresponding childTable rows, then the parentTable row.
- Arithmetic Errors – If an expression evaluation results in an arithmetic error, such as divide by zero, the DELETE is canceled an no rows removed.
Locking Behavior
A delete statement places an exclusive (X) lock on the table. This mean no other query can modify the table’s data until the DELETE transaction completes.
You can still read data, but need to use the NOLOCK hint or read uncommitted isolation level.
DELETE isn’t TRUNCATE!
Delete isn’t TRUNCATE! Use DELETE to remove one or more rows from a table. Only in special situation, such as when you need to reset a table to its initial state should you consider TRUNCATE.
Many people get DELETE and TRUNCATE mixed up.
Read More: What’s the Difference between Truncate and Delete in SQL Server? >>
DELETE Using a SubQuery
You can also create more complex delete statement. Just about any clause you can write into a SELECT statement WHERE clause, can be written into the DELETE statement’s, including subqueries in the WHERE clause.
Let’s do an example.
Suppose you need to remove all sales persons that live in the US from the esqlSalesPerson table. Though our table has City, it doesn’t have country. We can get around this by using a subquery.
BEGIN TRANSACTION SELECT COUNT(1) FROM esqlSalesPerson DELETE FROM esqlSalesPerson WHERE esqlSalesPerson.City IN (SELECT DISTINCT City FROM Person.Address A INNER JOIN Person.StateProvince S ON A.StateProvinceID = S.StateProvinceID AND S.CountryRegionCode = 'US' ) SELECT FullName, SalesLastYear FROM esqlSalesPerson ROLLBACK
Please Note, I wrapped the example in a transaction so I wouldn’t permanently delete my test data.
I colored the the subquery blue for easier spotting. Have you seen it is no different from any other correlated subquery you have used in the past?
The mechanics of this DELETE statement are:
- Find distinct cities for all people that live in the US.
- DELETE sales people whose city is in this list.
The first step results from the subquery. The second step deletes rows per the WHERE clause.